导语:为深入了解DeepSeek V3模型能力我们组织此次针对DeepSeek大模型的评测工作
2024年12月,幻方旗下深度求索公司上线DeepSeek V3系列模型首个版本,并同步开源模型和论文。为深入了解DeepSeek V3模型能力,新工业网组织此次针对DeepSeek大模型的评测工作,同时参与对比评测的大模型还有豆包(字节跳动)、通义千问(阿里巴巴)、文心一言(百度)、讯飞星火(科大讯飞),通过将DeepSeek与国内领先的AI大模型生成结果进行比较分析来判断DeepSeek性能表现,测试涵盖逻辑、数学、 代码、文本四大方案能力的8个问题,分别是:

逻辑:
( 1 )我的住处在城市和农场之间,农场在城市和机场之间,所以农场到我的住处的距离比到机场近,这个正确吗?
(2)我们采用Base64的编码方法对“This is a new large language model”编码为 “VGhpcyBpcyBhlG5ldyBsYXJnZSBsYW5ndWFnZSBtb2RbA== ”
使用上面的例子来解
“VGhlIE1vZGVsIHRyYWluZWQgd2l0aCByZWluZm9yY2VtZW50IGxlYXJuaW5n IHRvIHBlcmZvcm0gY29tcGxleCByZWFzb25pbmc= ”
数学:
(3)一个圆柱体垂直放置在一个水平面上,其底面直径为d,高为H。请画出这个圆柱体在水平面上的正投影和侧投影,并计算这些投影的面积。请详细解释你的推理和计算过程。
(4)有100名员工去年和今年均参加考核,考核结果分为优、良、中、差四个等次。今年考核结果为优的人数是去年的1.2倍,今年考核结果为良及以下的人员占比比去年低15个百分点。问两年考核结果均为优的人数至少为多少人?
代码:
(5)请用Python语言写一段代码,找出从1到100内所有的质数。
(6)假设你需要为一个电子商务网站开发一个功能,允许用户根据价格范围和产品类别筛选商品。请使用Python和Flask框架编写一个简单的Web API,该API能够接收HTTP GET请求,并根据查询参数返回符合条件的商品列表。
文本:
(7)请选择一个你最喜欢的季节,详细描述该季节的自然景观、气候特点以及人们的生活状态,字数控制在500字以内。
(8)假设你需要向一家公司申请实习机会,请撰写一封正式的求职信。信中需包括你的教育背景、相关经验和个人优势,并表达你对该公司和实习职位的兴趣。
(一)逻辑
( 1 )我的住处在城市和农场之间,农场在城市和机场之间,所以农场到我的住处的距离比到机场近,这个正确吗?
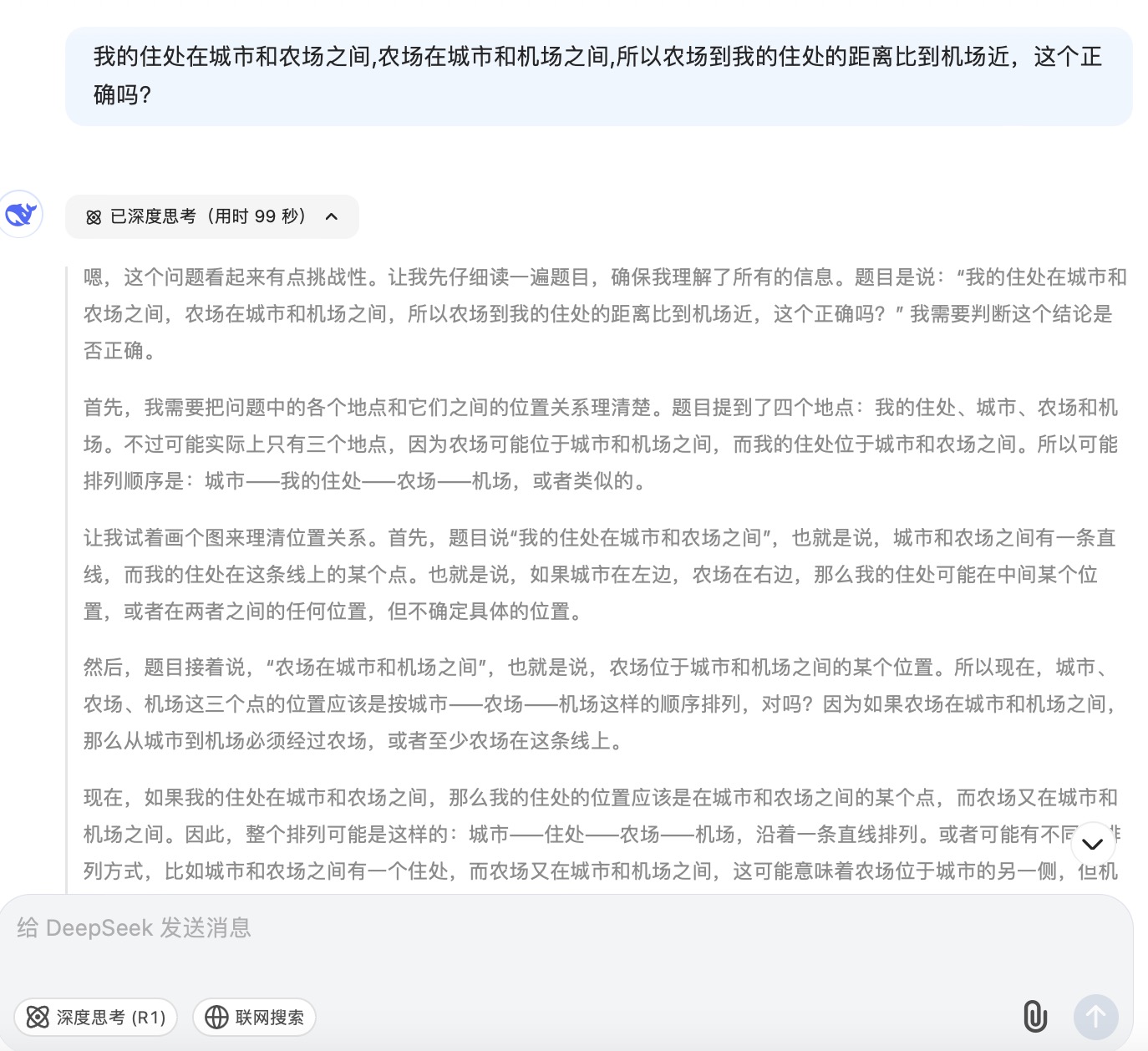
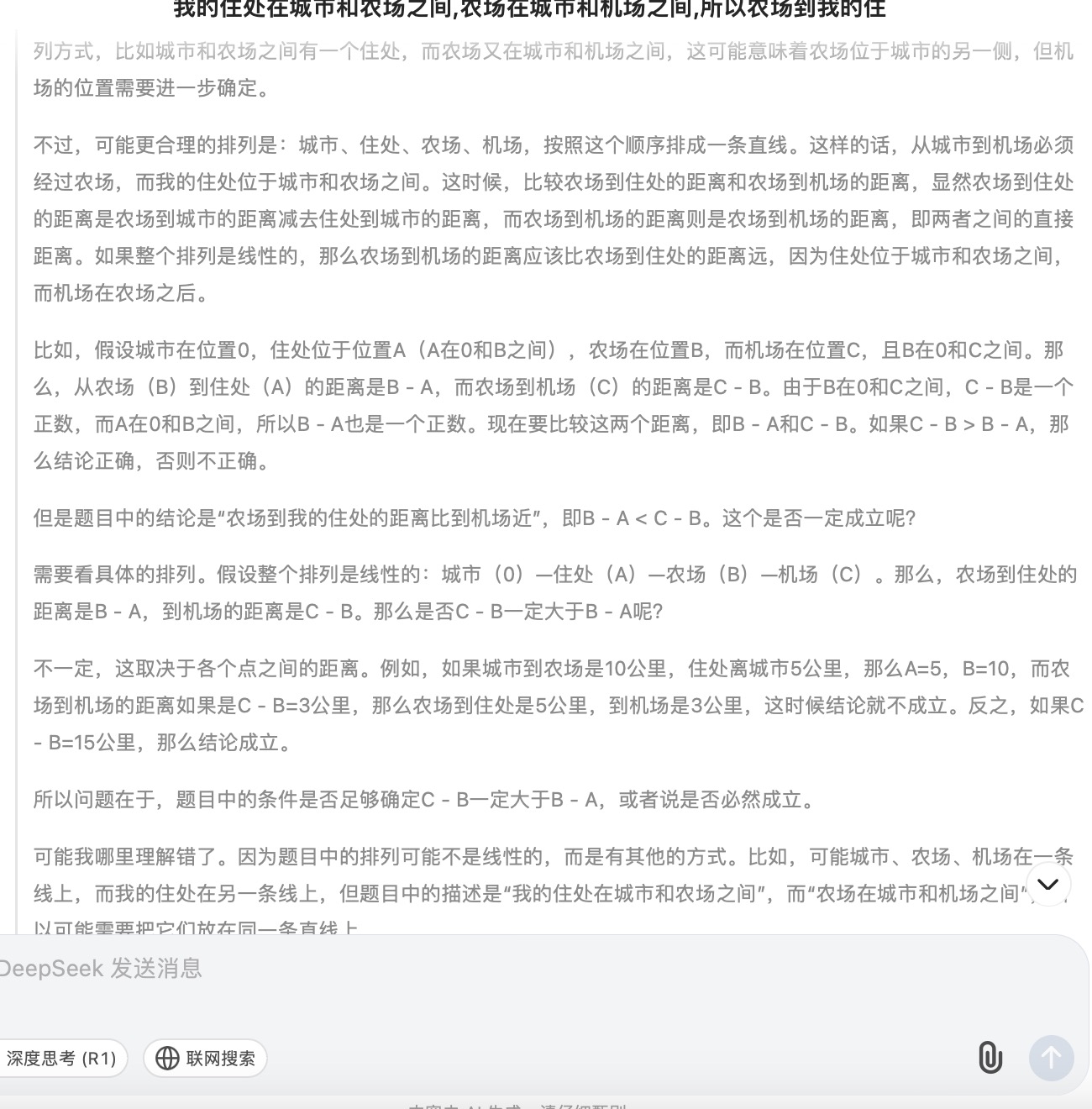
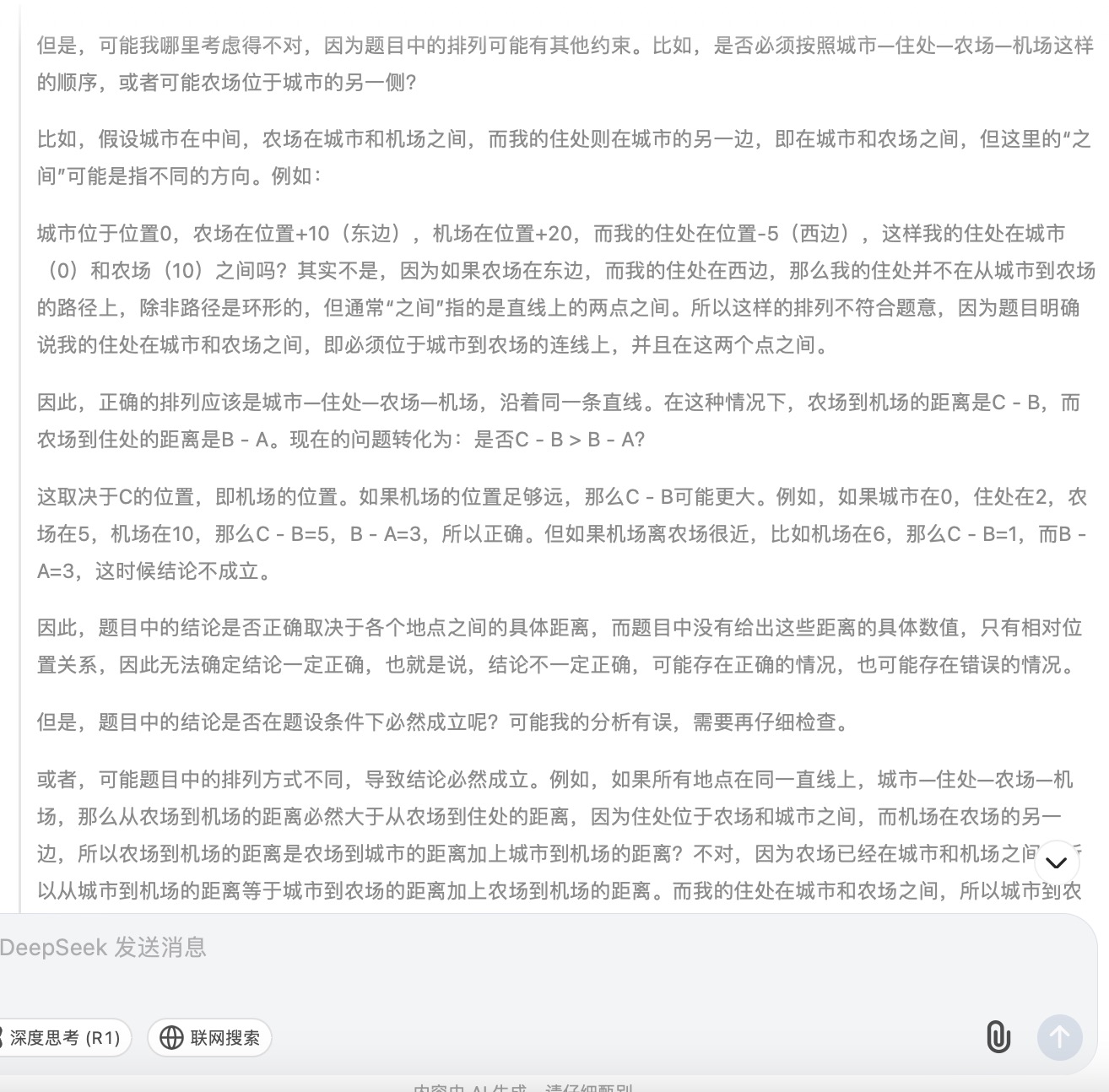
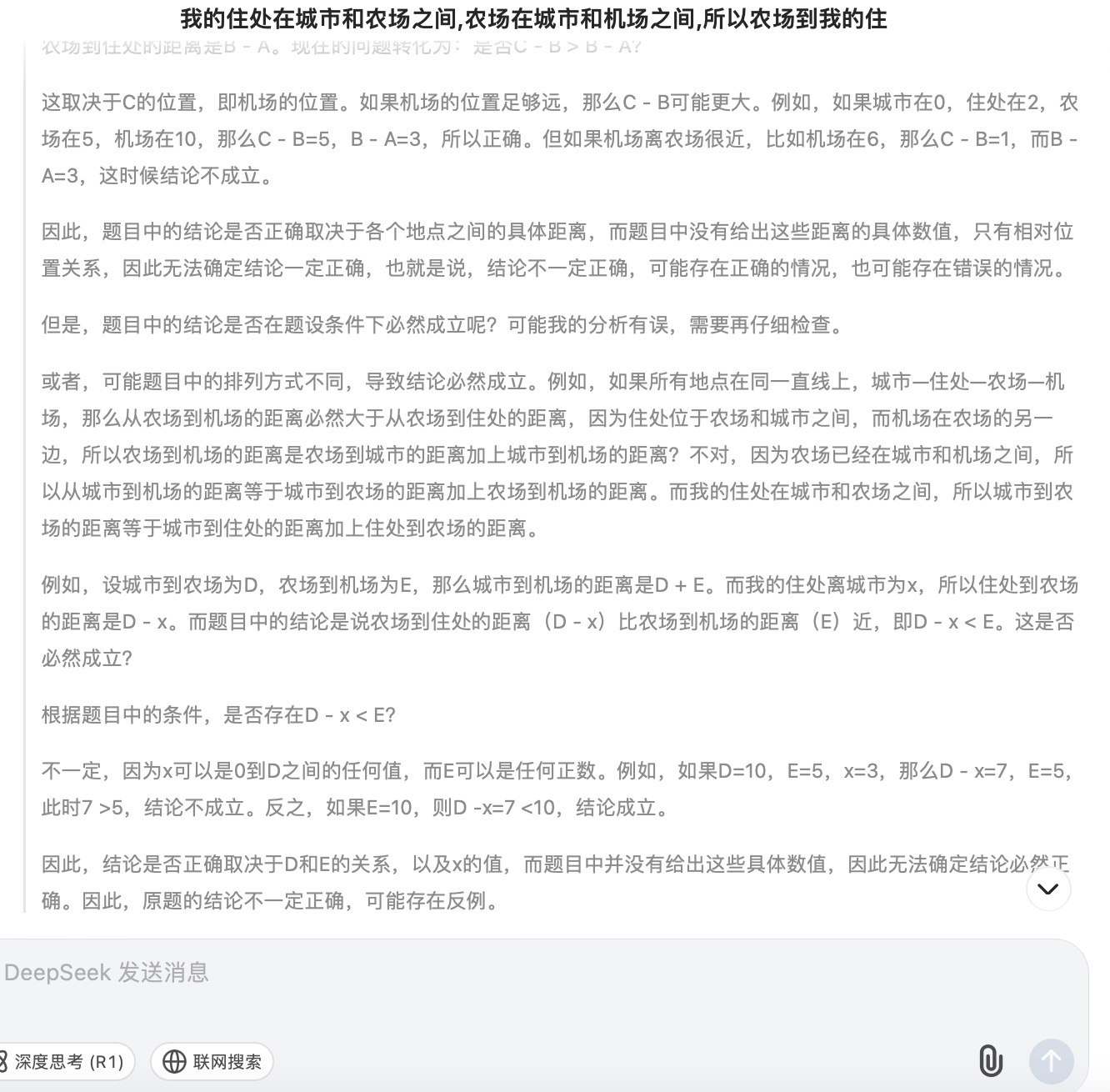

DeepSeek大模型对问题(1)的回答
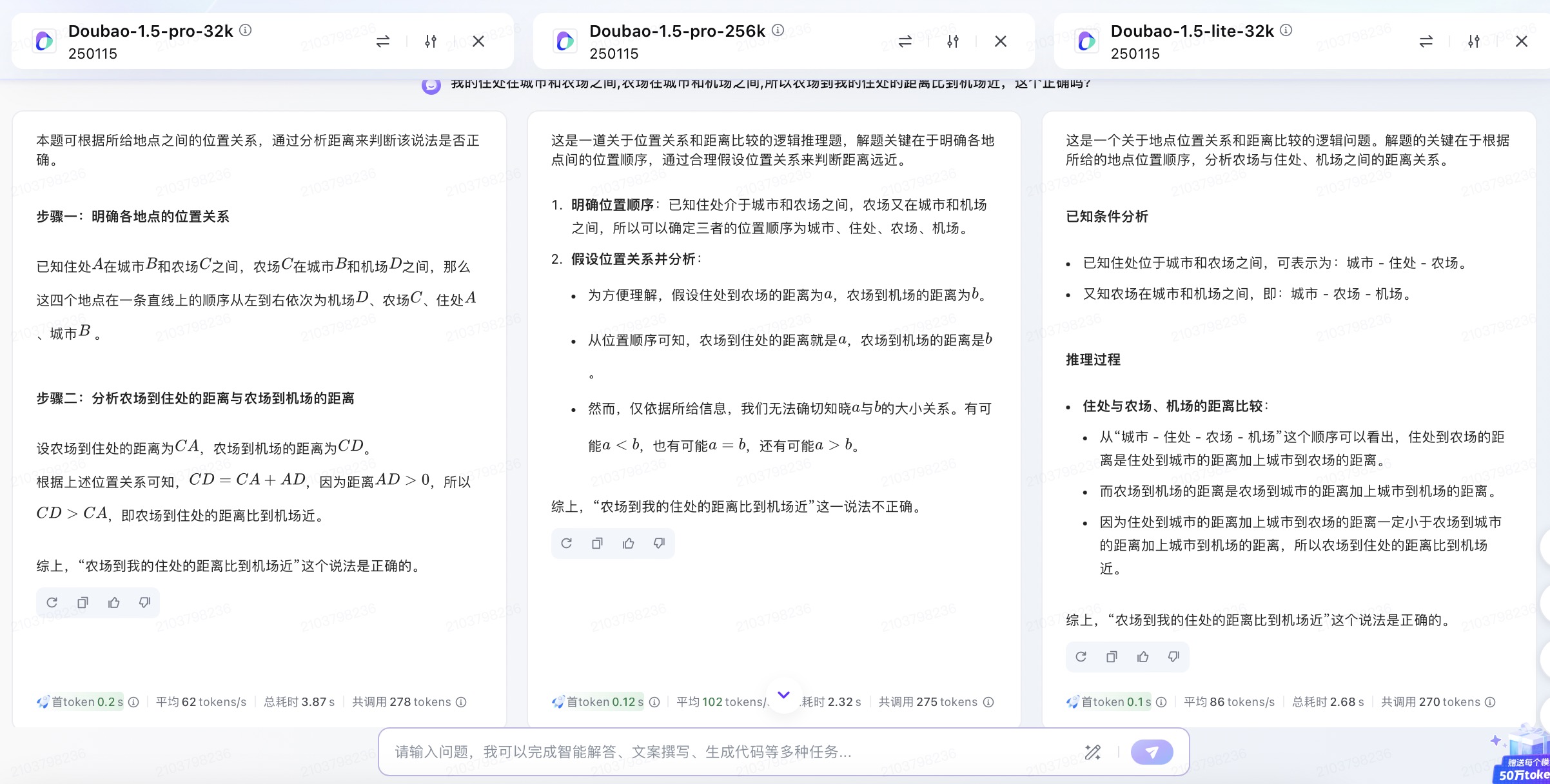
豆包大模型对问题(1)的回答
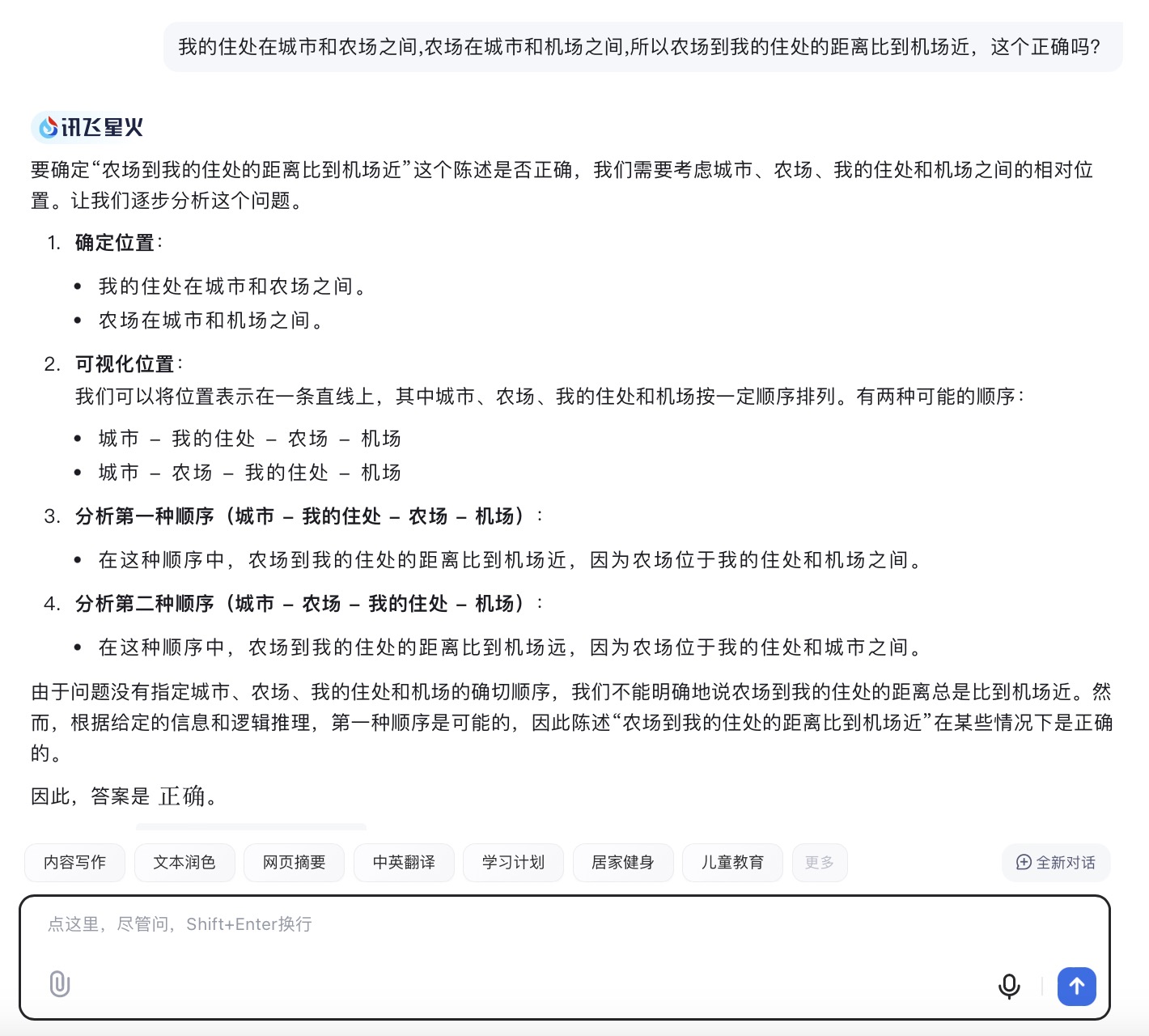
讯飞星火大模型对问题(1)的回答

通义千问大模型对问题(1)的回答

文心一言大模型对问题(1)的回答
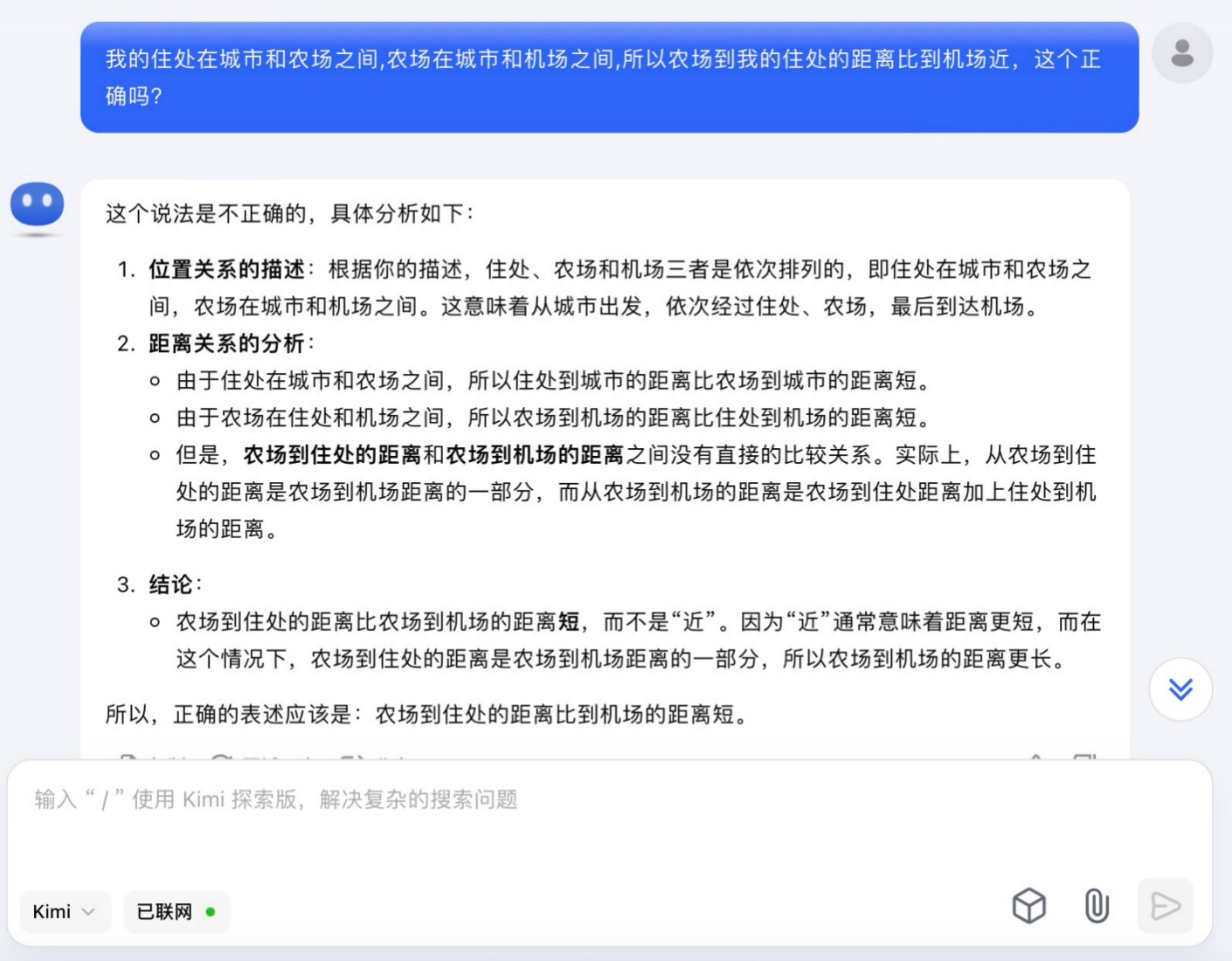
Kimi大模型对问题(1)的回答
问题(1)主要考察大模型的空间理解和推理能力。通义千问根据文字描述推断出“机场-农场-城市-您的住处”或“你的住处-城市-农场-机场”,在这一步推理中即出现了错误。讯飞星火则假设了“城市-你的住处-农场-机场”和“城市-农场-你的住处-机场”两种情况分别讨论,这两种情况都是可能存在的;文心一言、豆包、Kimi按照直线以“城市-你的住处-农场-机场”顺序进行推理,但文心一言得到的答案依然是错误的,因为空间位置的分布应该在二维平面上进行比较,而不是单一维度的比较大小。针对此问题,最终贴近正确结果的是DeepSeek,其得到的结论“距离的远近取决于具体各个地点之间的实际路程长短,不能仅凭相对位置关系简单判定。”但所有模型在推理问题时,主要以线性来分析问题,未能更多地体现出二维平面空间的位置排列。
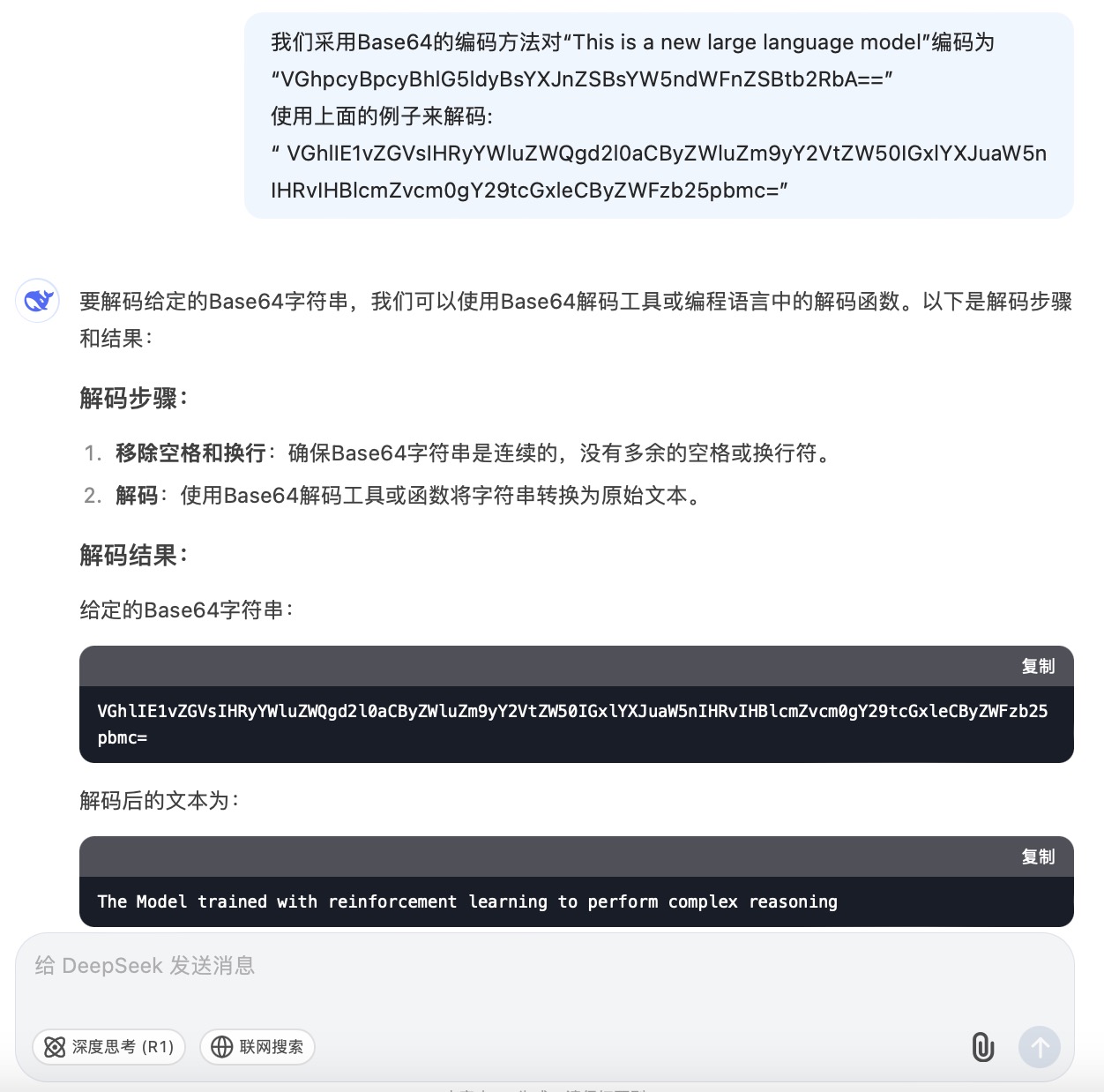
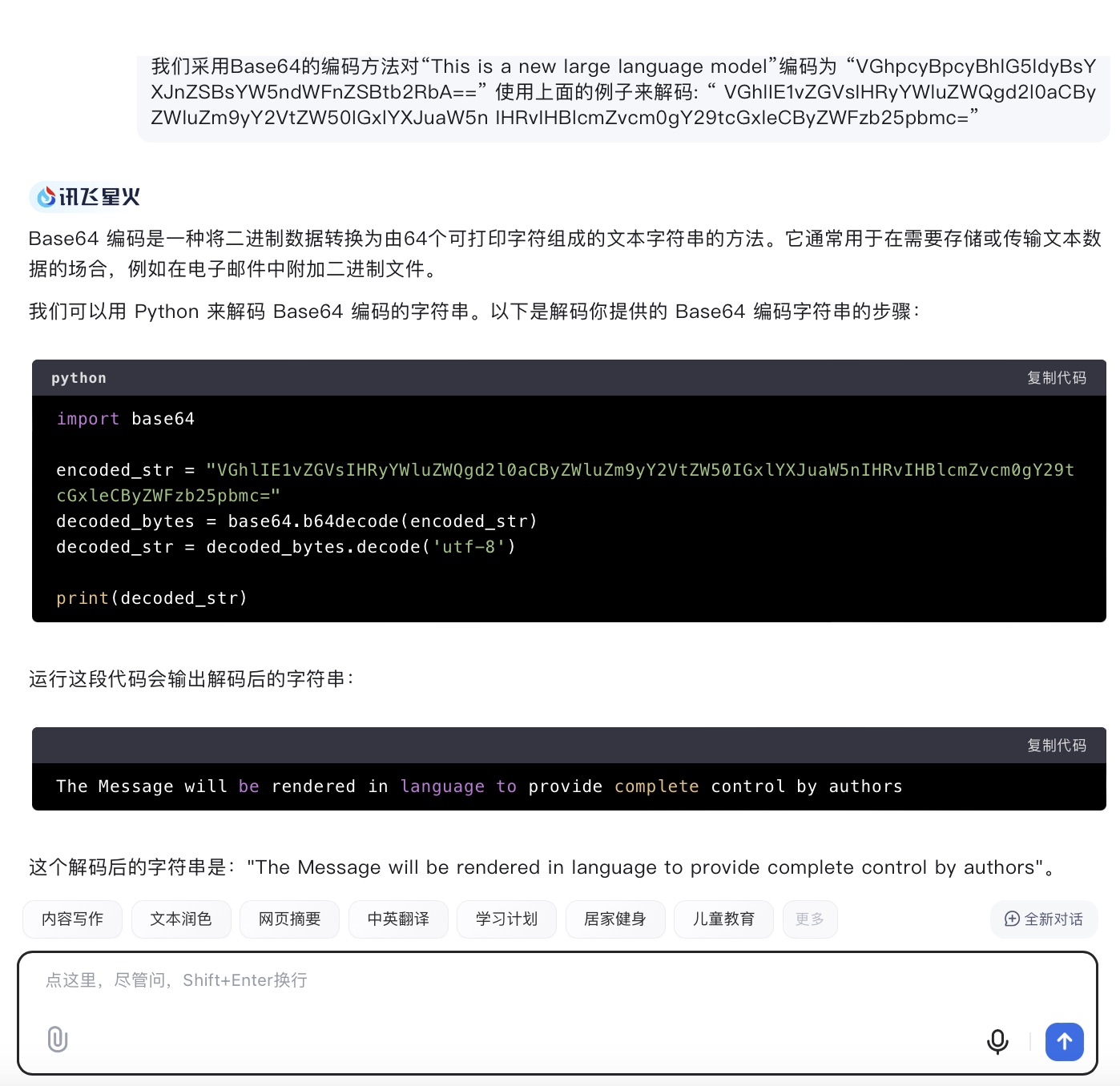
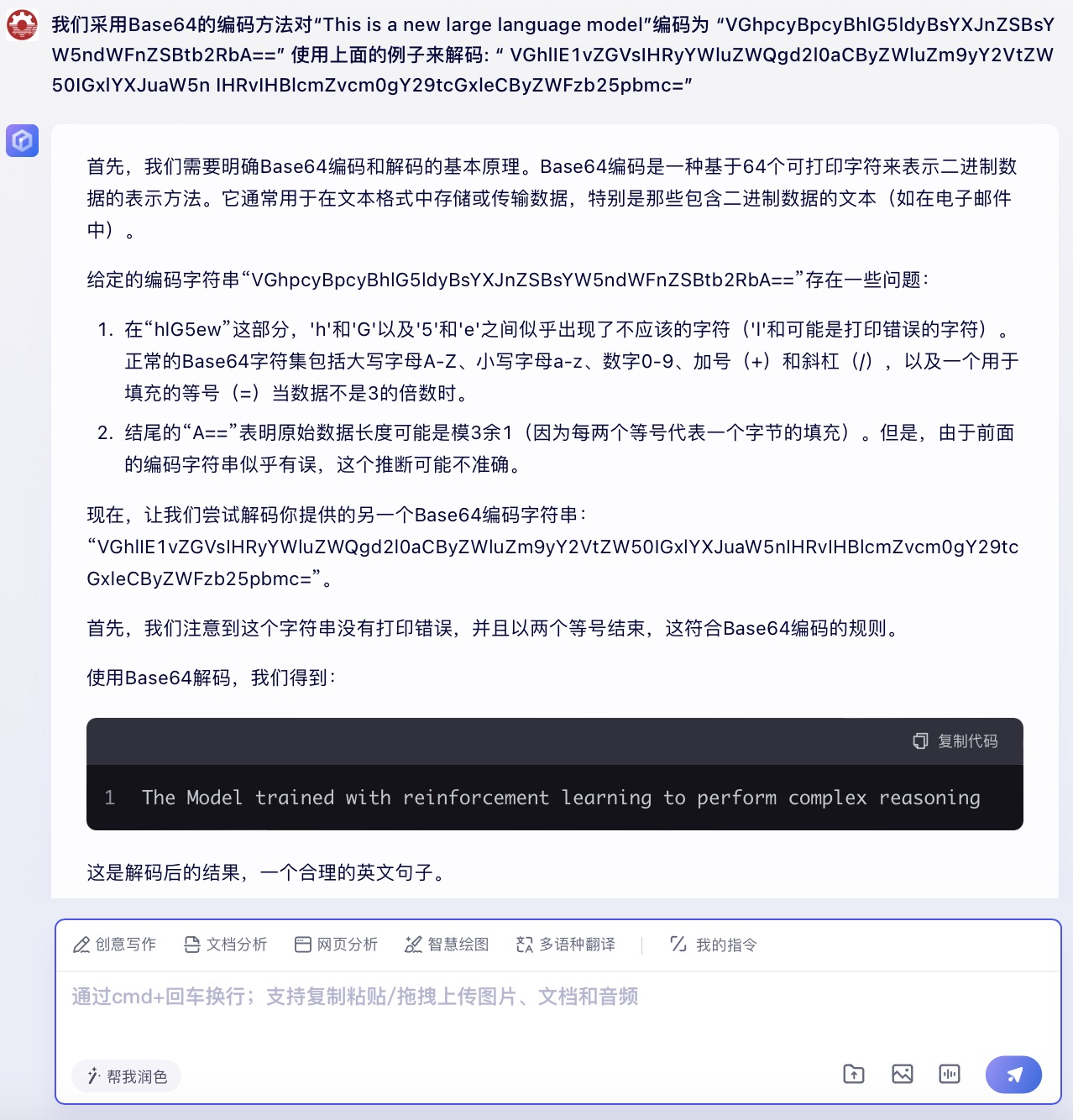
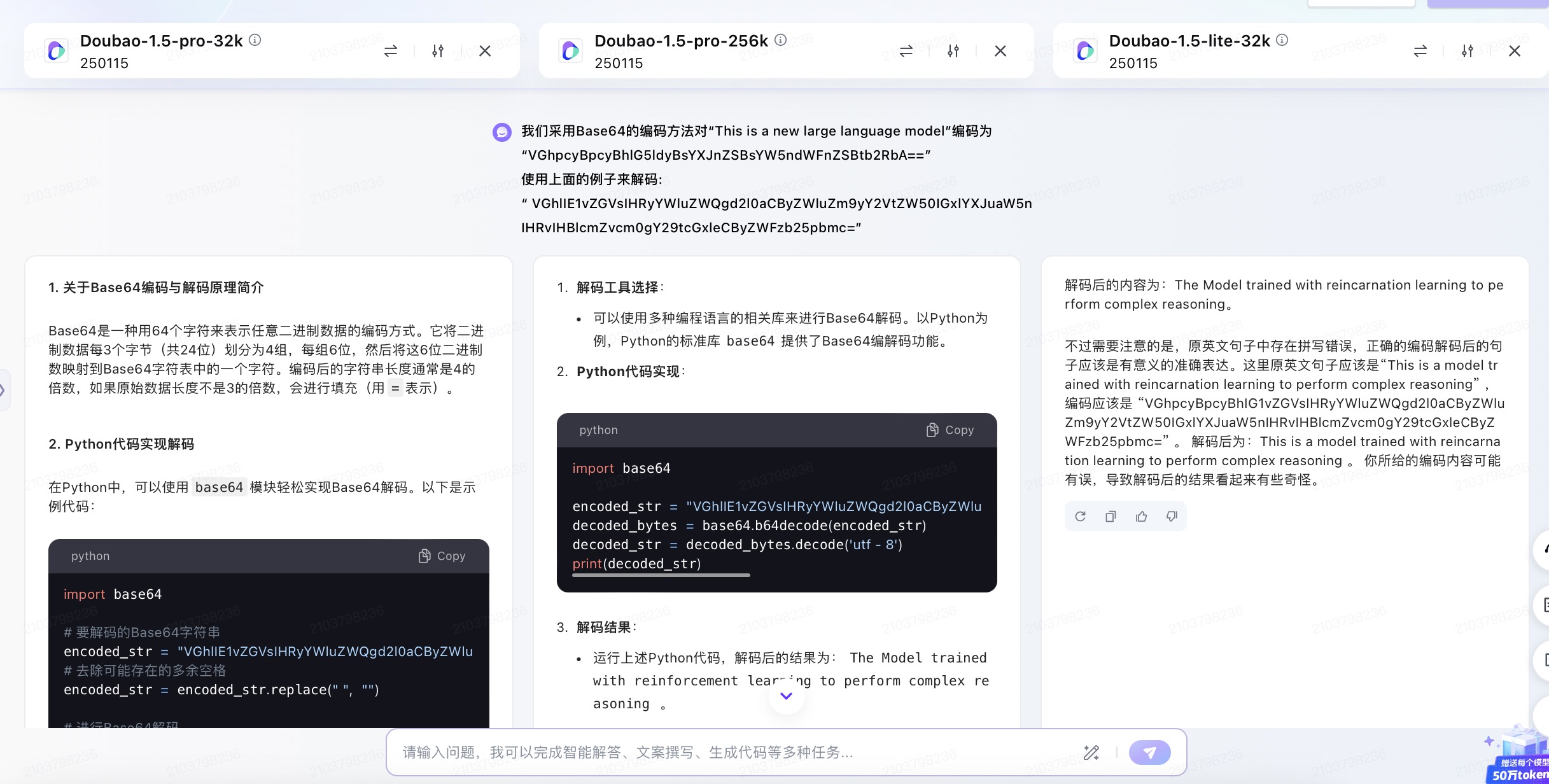
(2)我们采用Base64的编码方法对“This is a new large language model”编码为 “VGhpcyBpcyBhlG5ldyBsYXJnZSBsYW5ndWFnZSBtb2RbA== ”
使用上面的例子来解
“VGhlIE1vZGVsIHRyYWluZWQgd2l0aCByZWluZm9yY2VtZW50IGxlYXJuaW5n IHRvIHBlcmZvcm0gY29tcGxleCByZWFzb25pbmc= ”
DeepSeek大模型对问题(2)的回答
讯飞星火大模型对问题(2)的回答

通义千问大模型对问题(2)的回答
文心一言大模型对问题(2)的回答

豆包大模型对问题(2)的回答
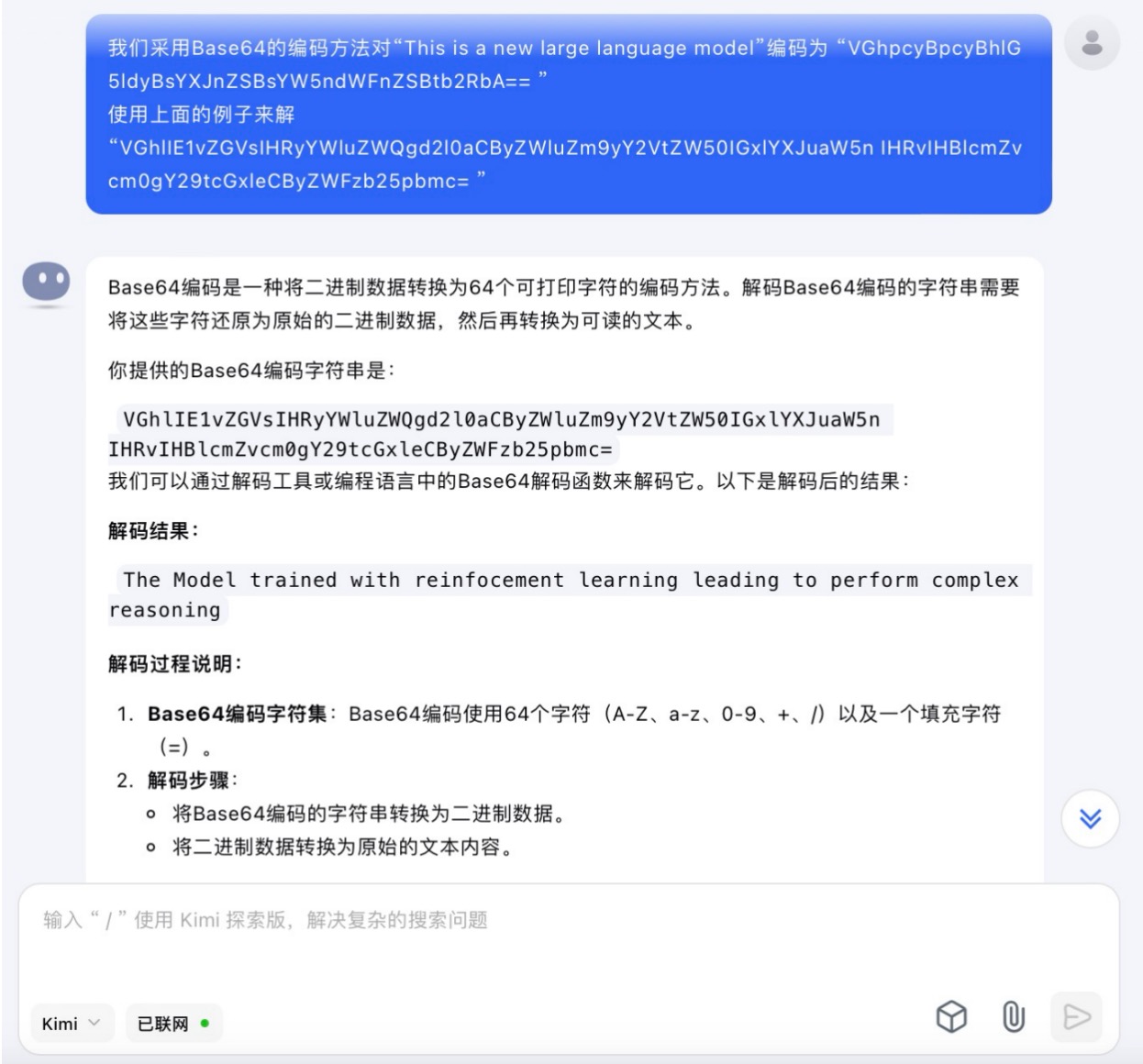
Kimi大模型对问题(2)的回答
问题(2)是考察大模型密文解码能力。6个大模型都理解了示例中的编码方式是采用Base64的方法。其中,DeepSeek、豆包、文心一言、通义千问、Kimi对于密文解码后得到了正确文本“The Model trained with reinforcement learning to perform complex reasoning”。而讯飞星火大模型解码后的结果与正确答案相差较大。
(二)数学
(3)一个圆柱体垂直放置在一个水平面上,其底面直径为d,高为H。请画出这个圆柱体在水平面上的正投影和侧投影,并计算这些投影的面积。请详细解释你的推理和计算过程。
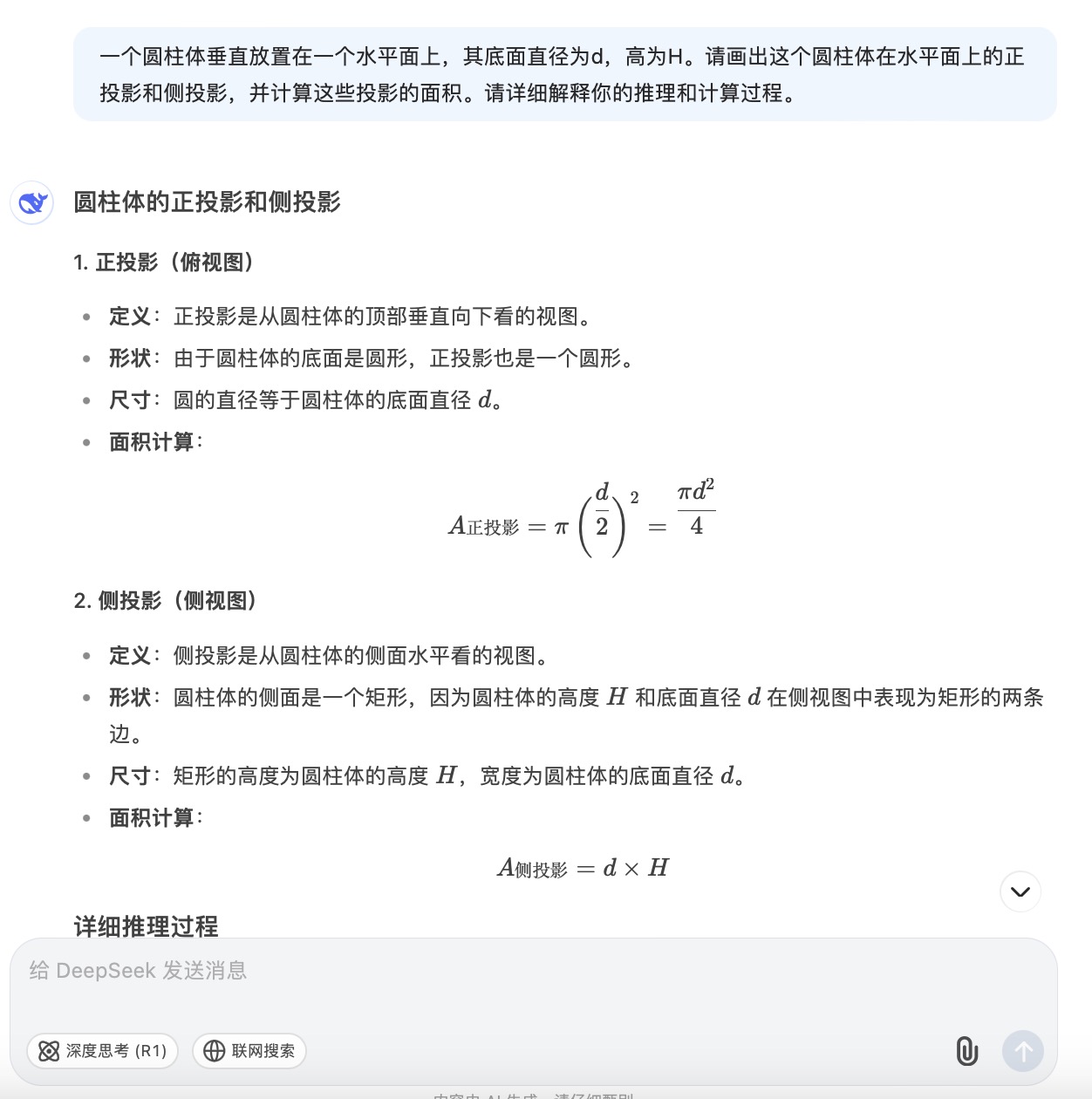

DeepSeek大模型对问题(3)的回答
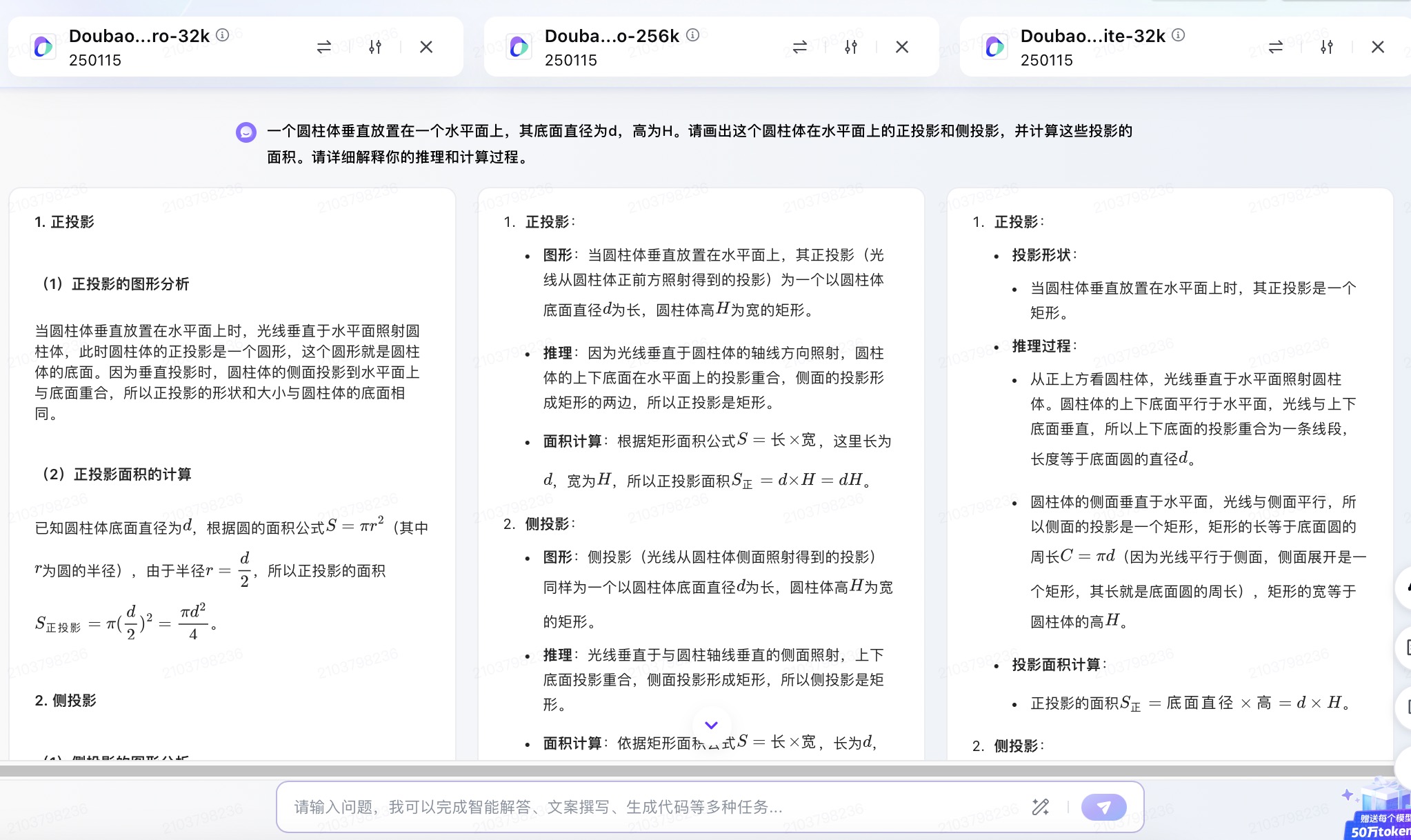
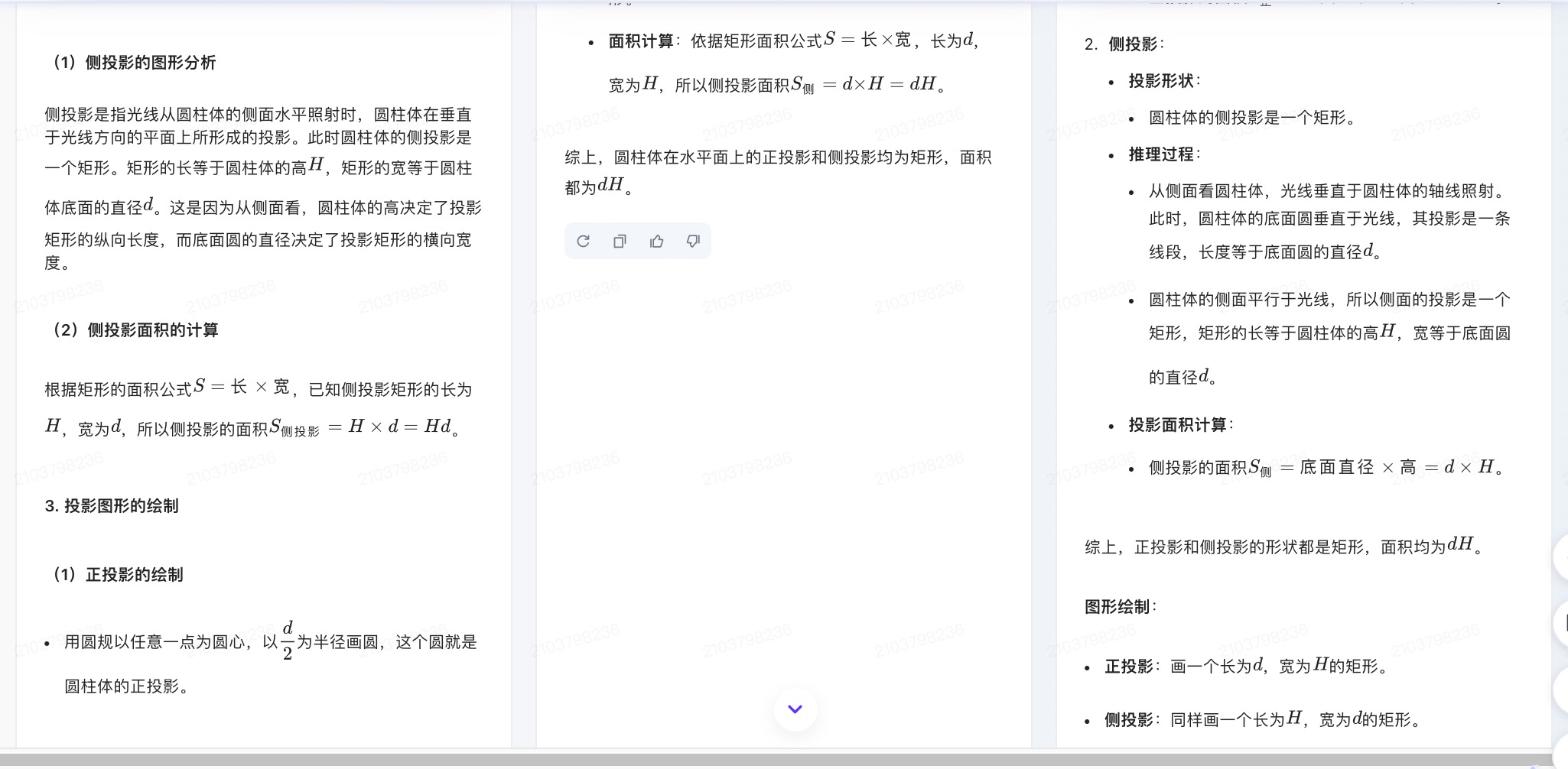
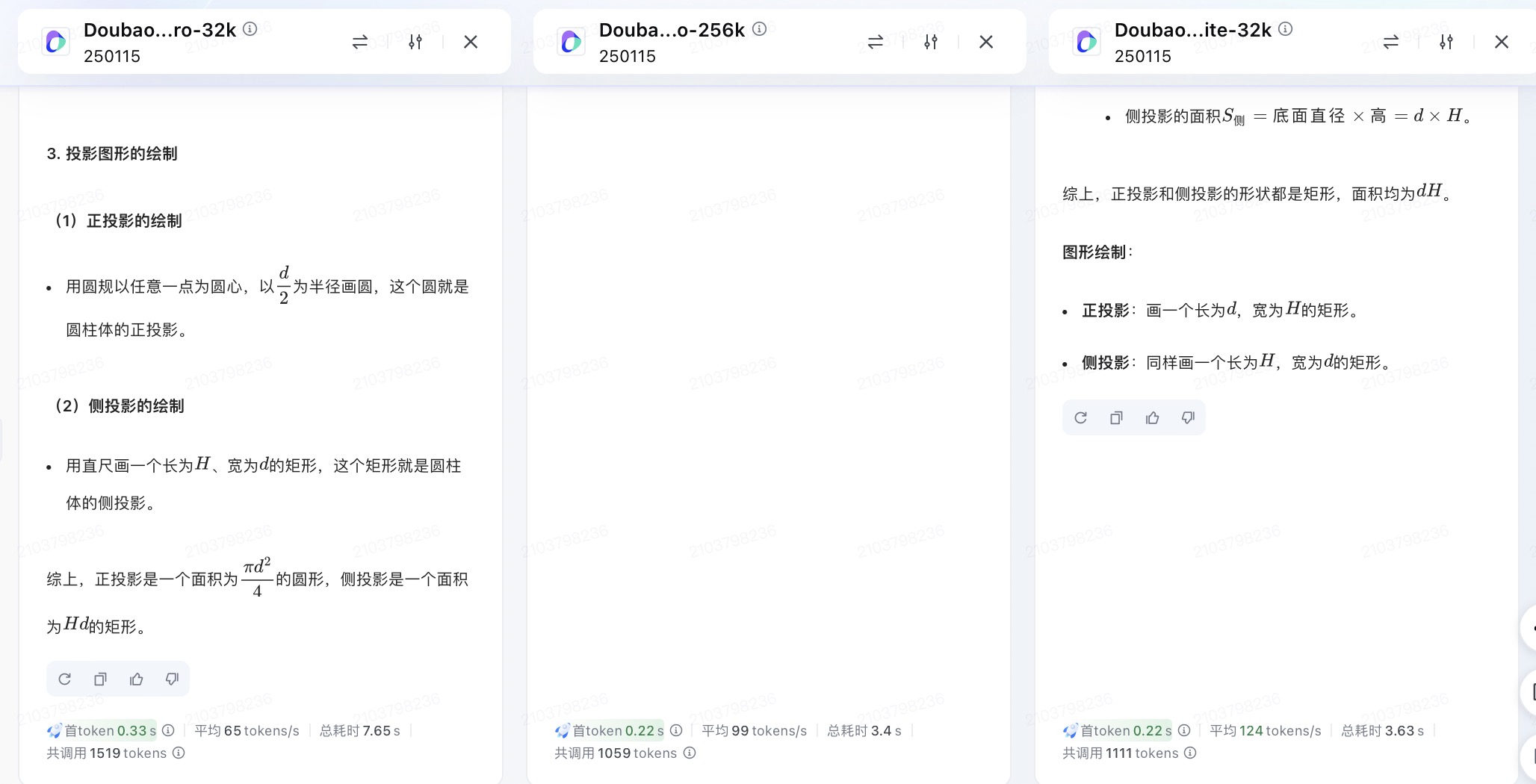
豆包大模型对问题(3)的回答
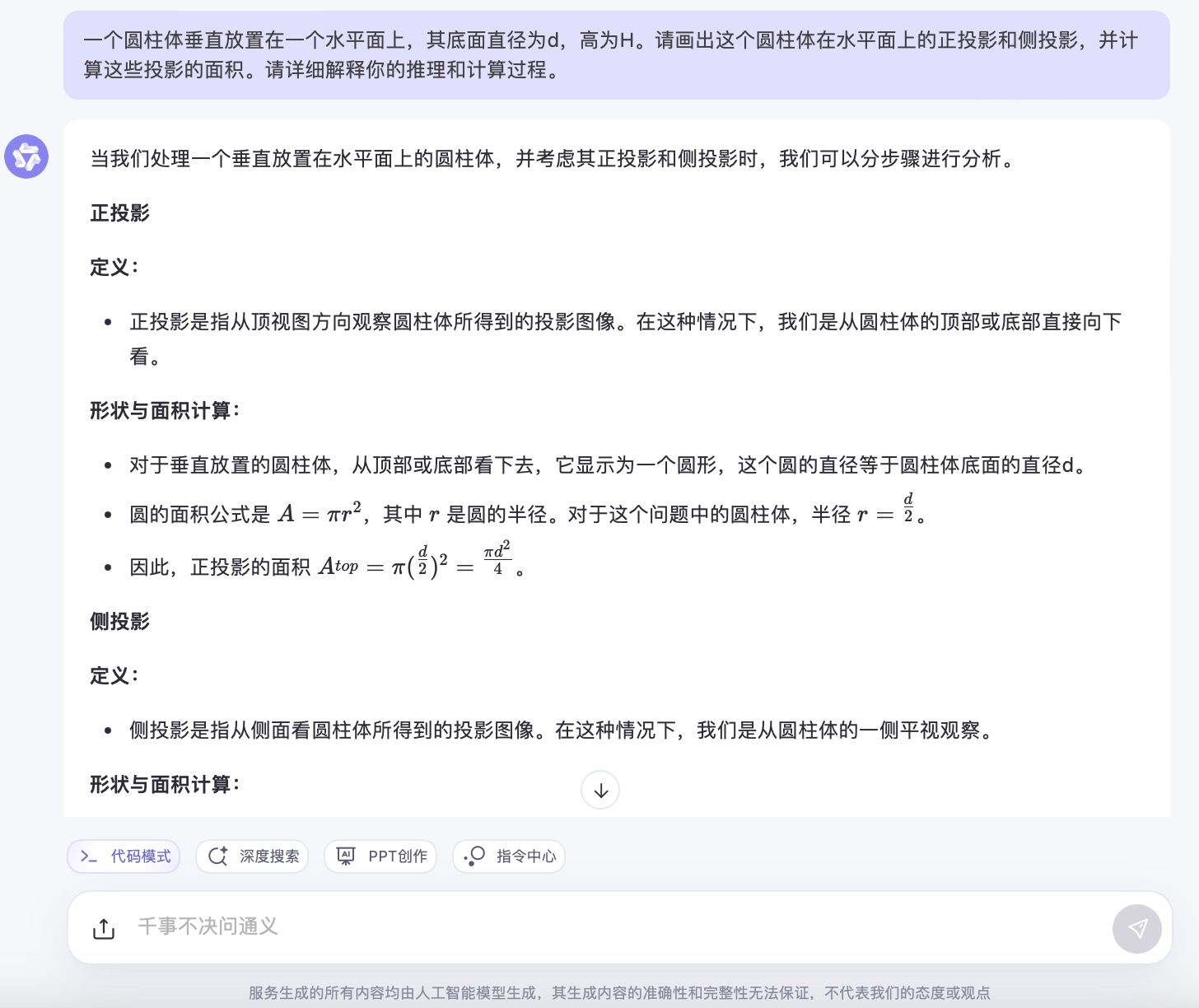
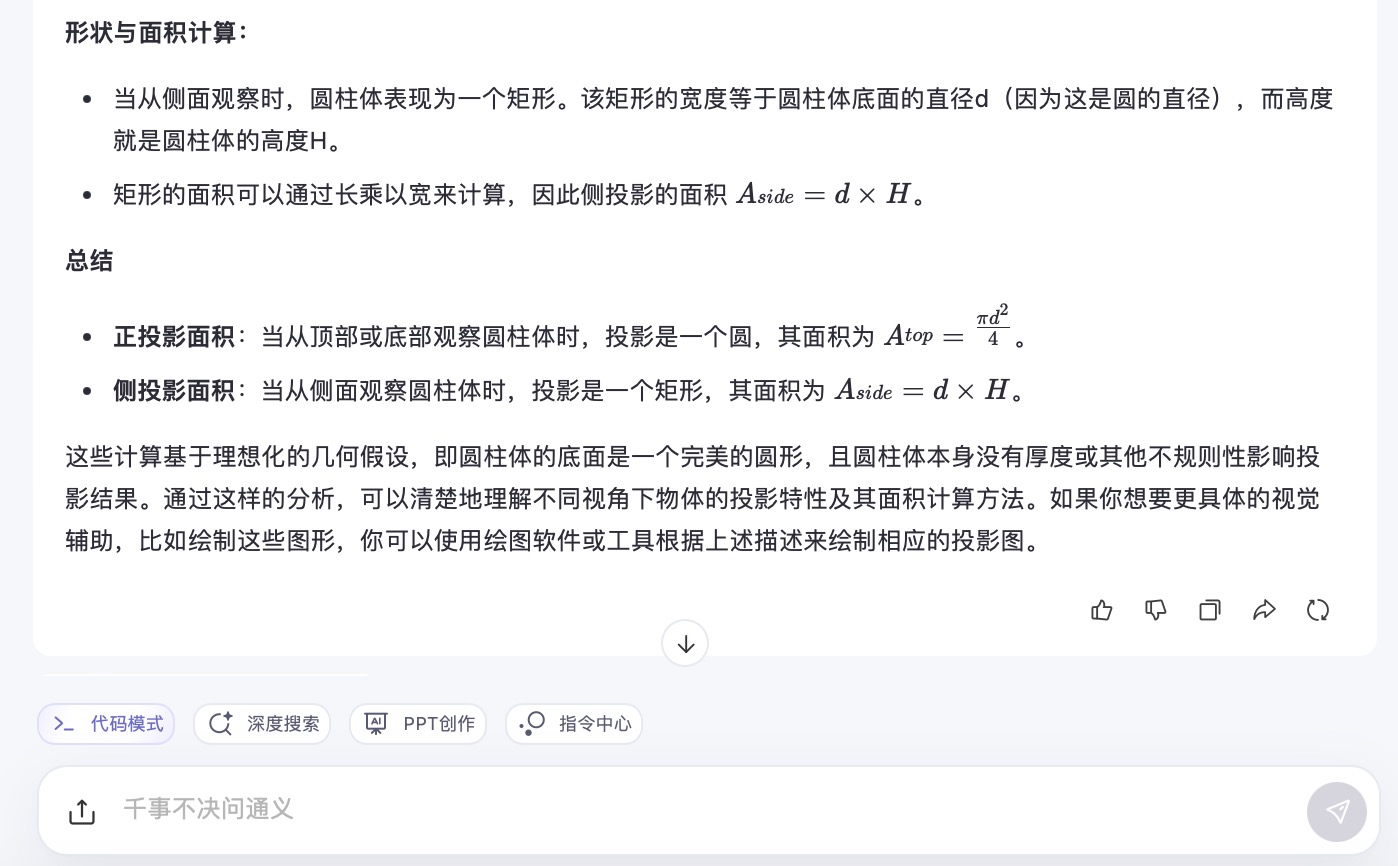
通义千问大模型对问题(3)的回答

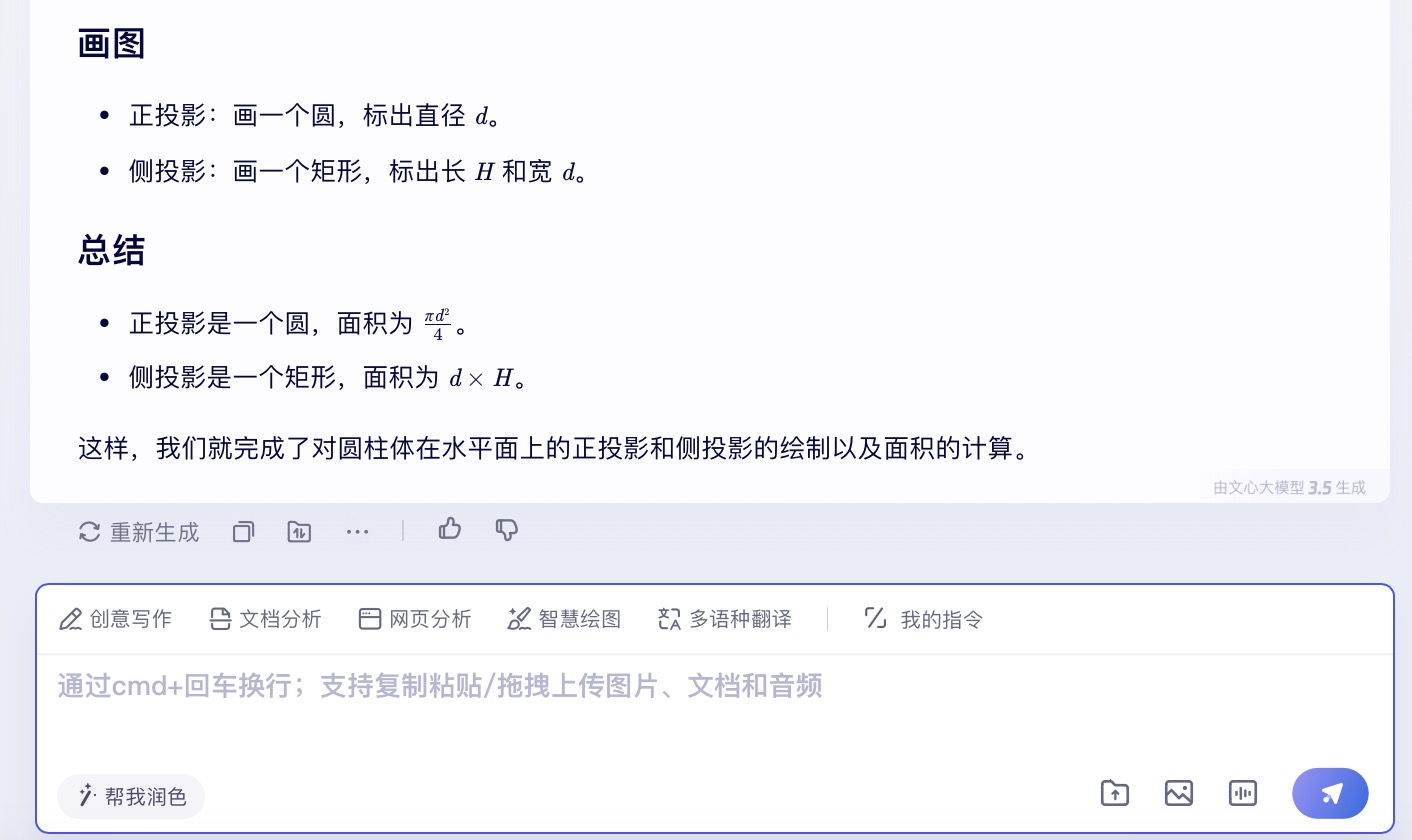
文心一言大模型对问题(3)的回答
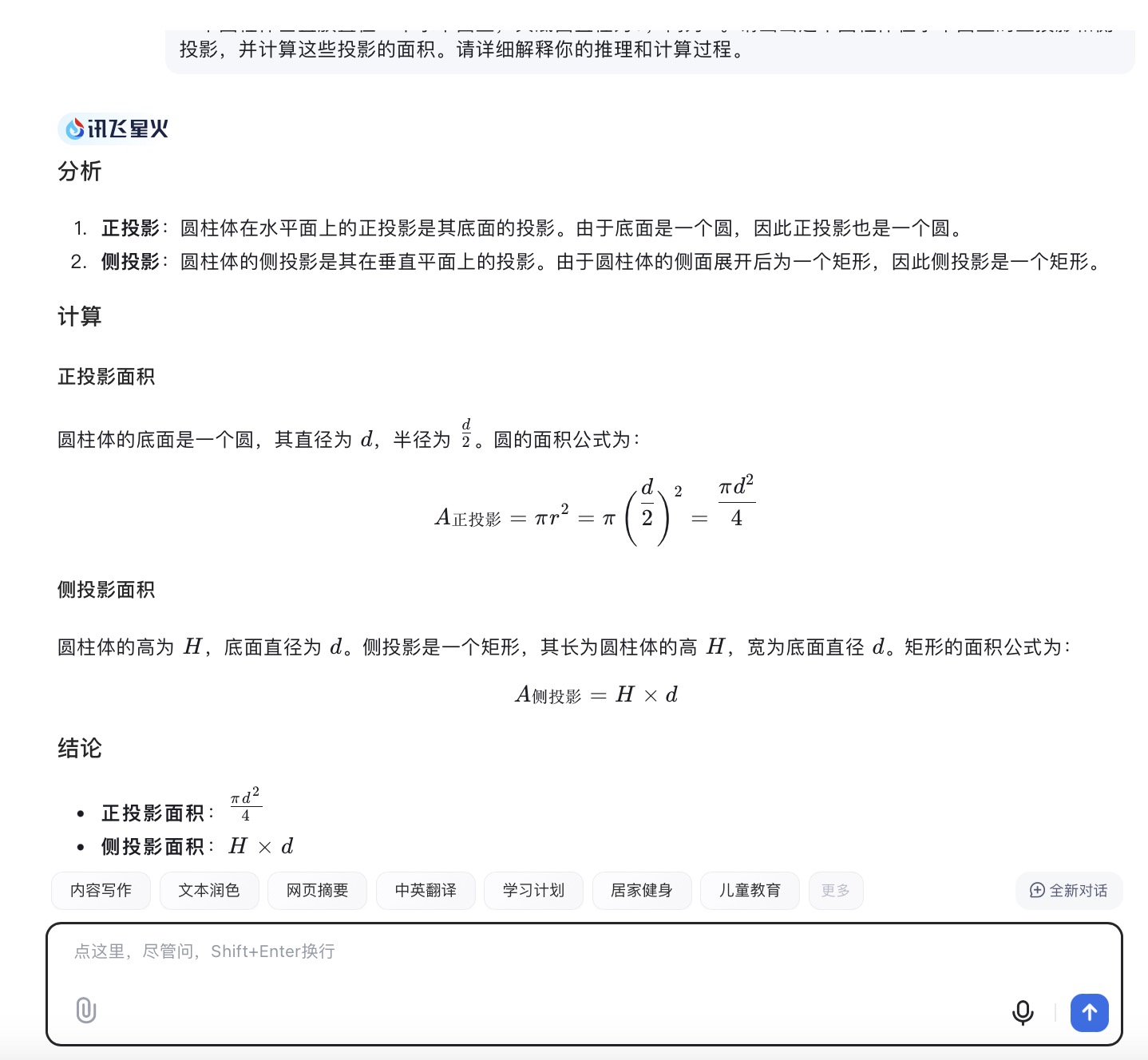
讯飞星火大模型对问题(3)的回答


Kimi大模型对问题(3)的回答
问题(3)是考察大模型空间几何理解和计算能力。从测试的结果来看,DeepSeek、文心一言、通义千问、讯飞星火、Kimi给出了详细的计算过程,并且计算所得结果都是正确的,但并未执行用户提出的指令“画出圆柱体在水平面上的正投影和侧投影”。此外,DeepSeek为方便用户理解,还能够给出假设数据并计算具体案例,也是唯一给出计算案例的大模型。在三个不同版本的豆包大模型中,仅Doubao-1.5-pro-32kz版本给出了正确答案,其它的两个计算圆柱体正投影的答案出现了错误。
(4)有100名员工去年和今年均参加考核,考核结果分为优、良、中、差四个等次。 今年考核结果为优的人数是去年的1.2倍,今年考核结果为良及以下的人员占比比去年低15个百分点。问两年考核结果均为优的人数至少为多少人?
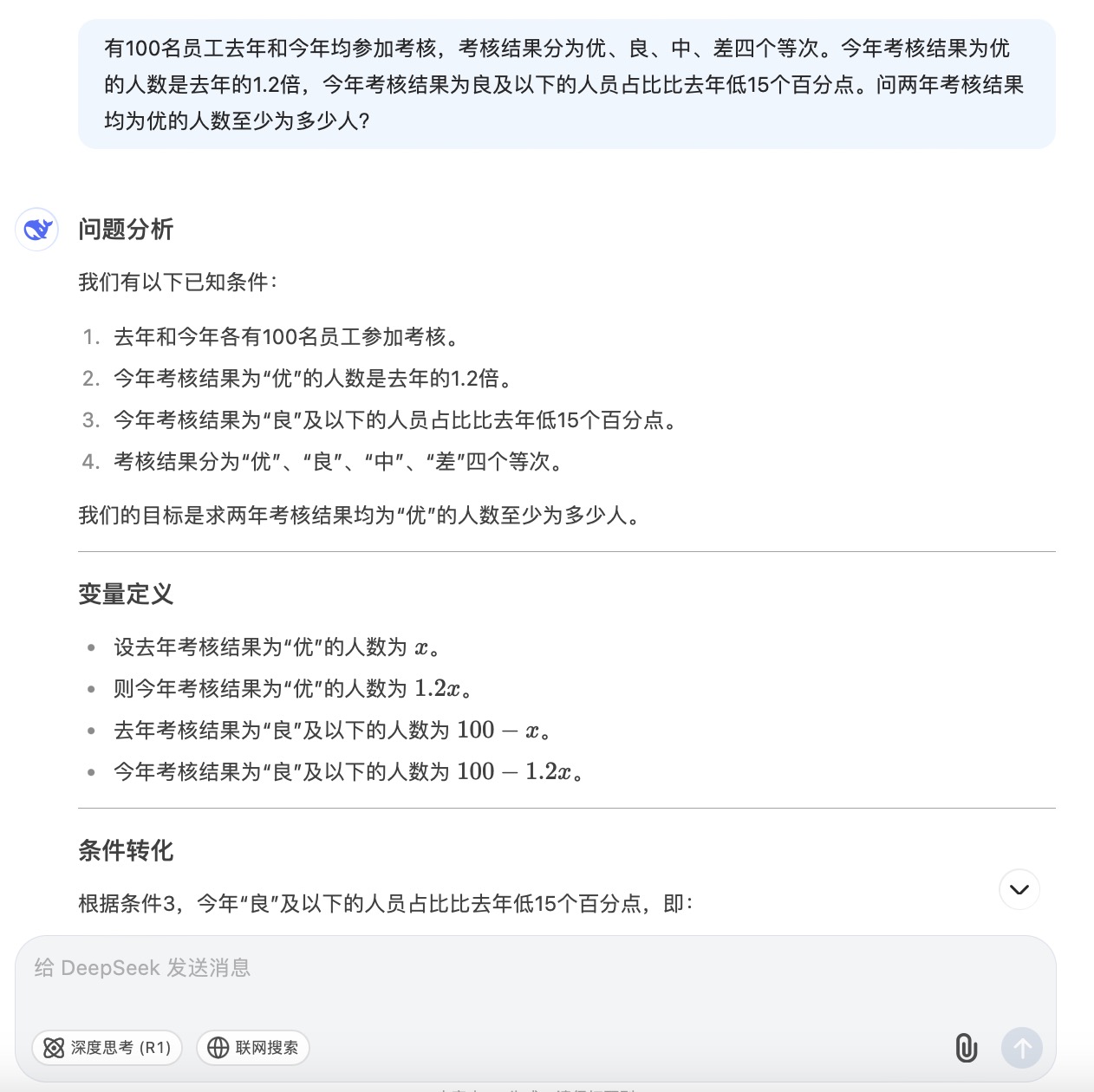

DeepSeek大模型对问题(4)的回答
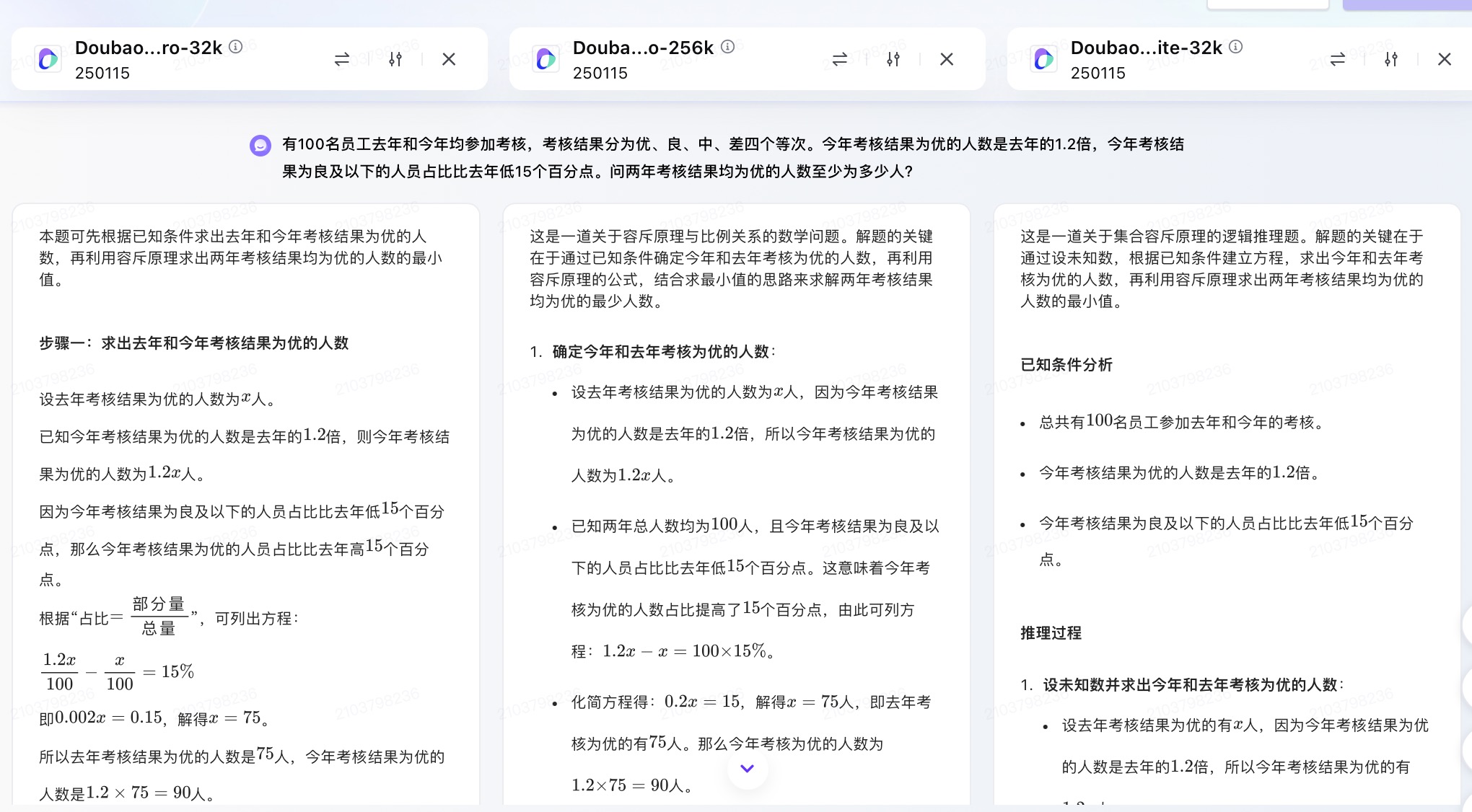
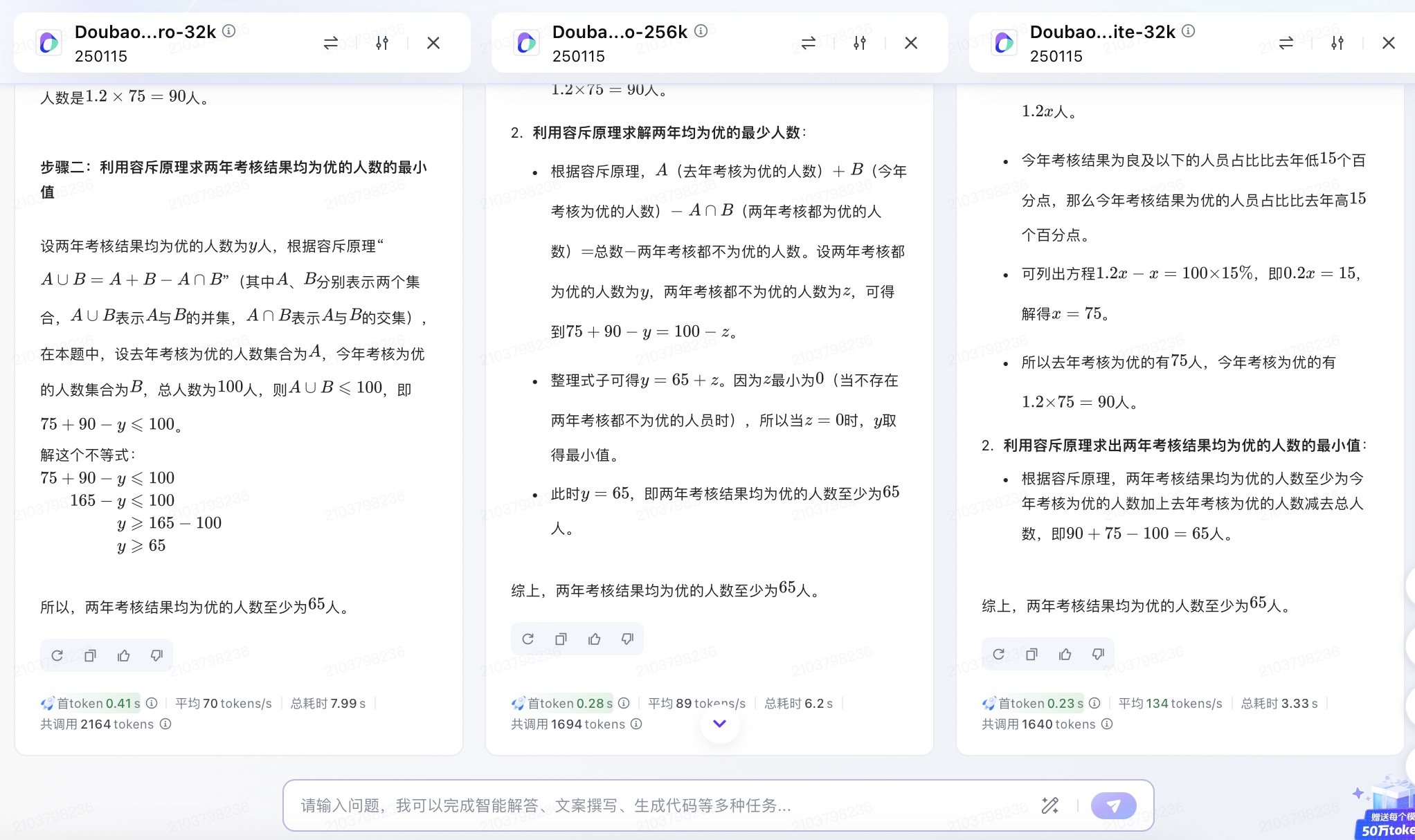
豆包大模型对问题(4)的回答
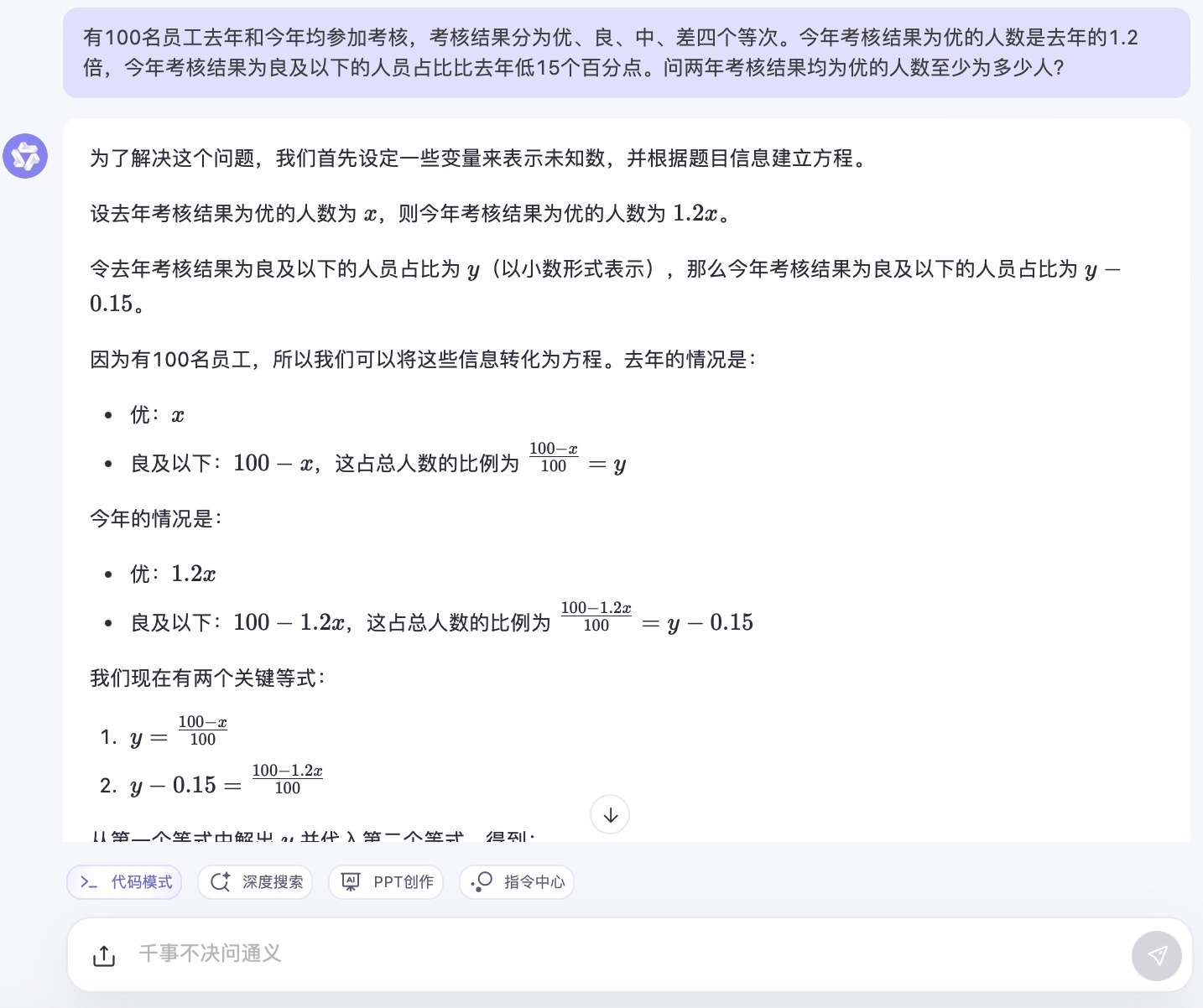
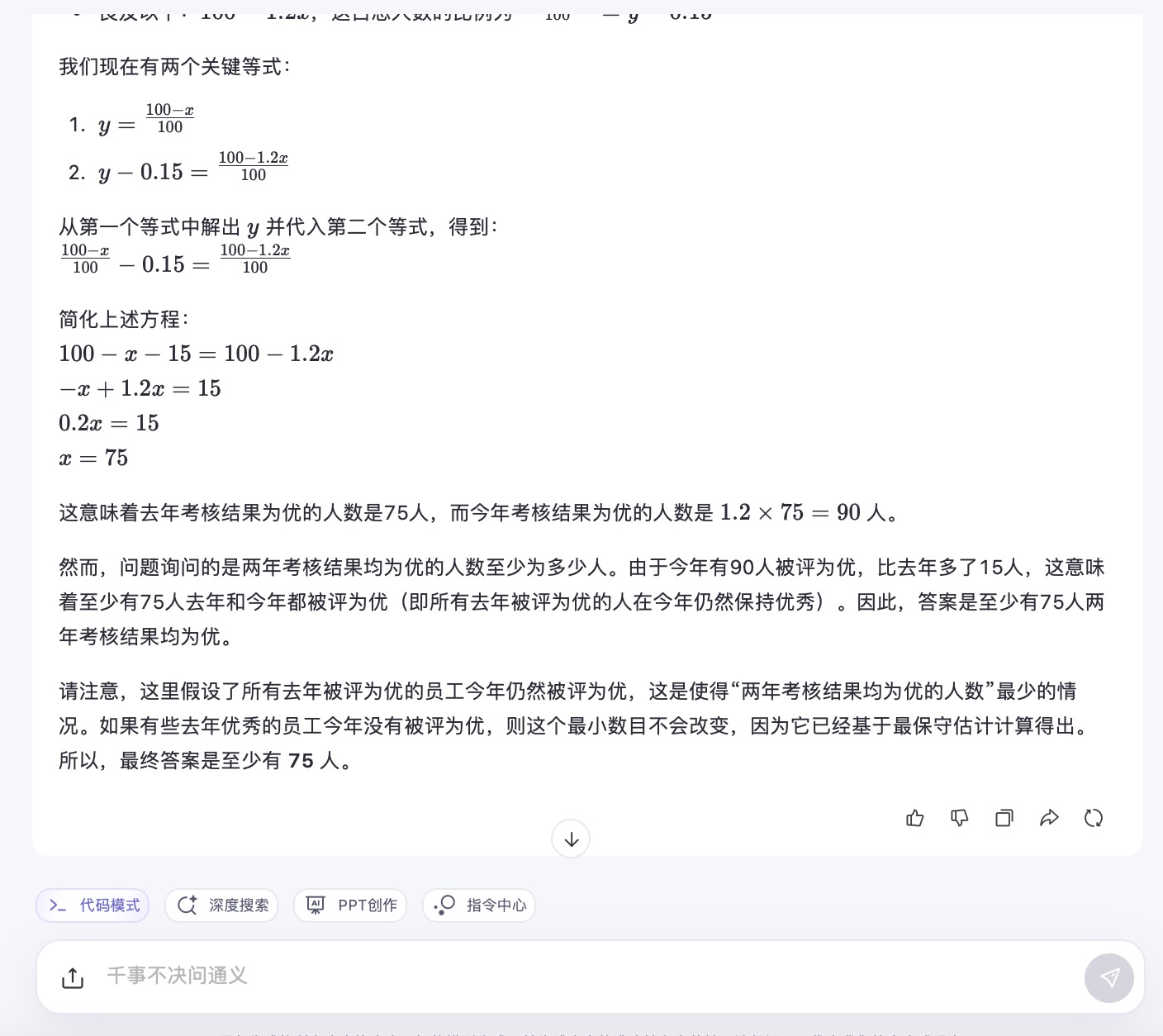
通义千问大模型对问题(4)的回答
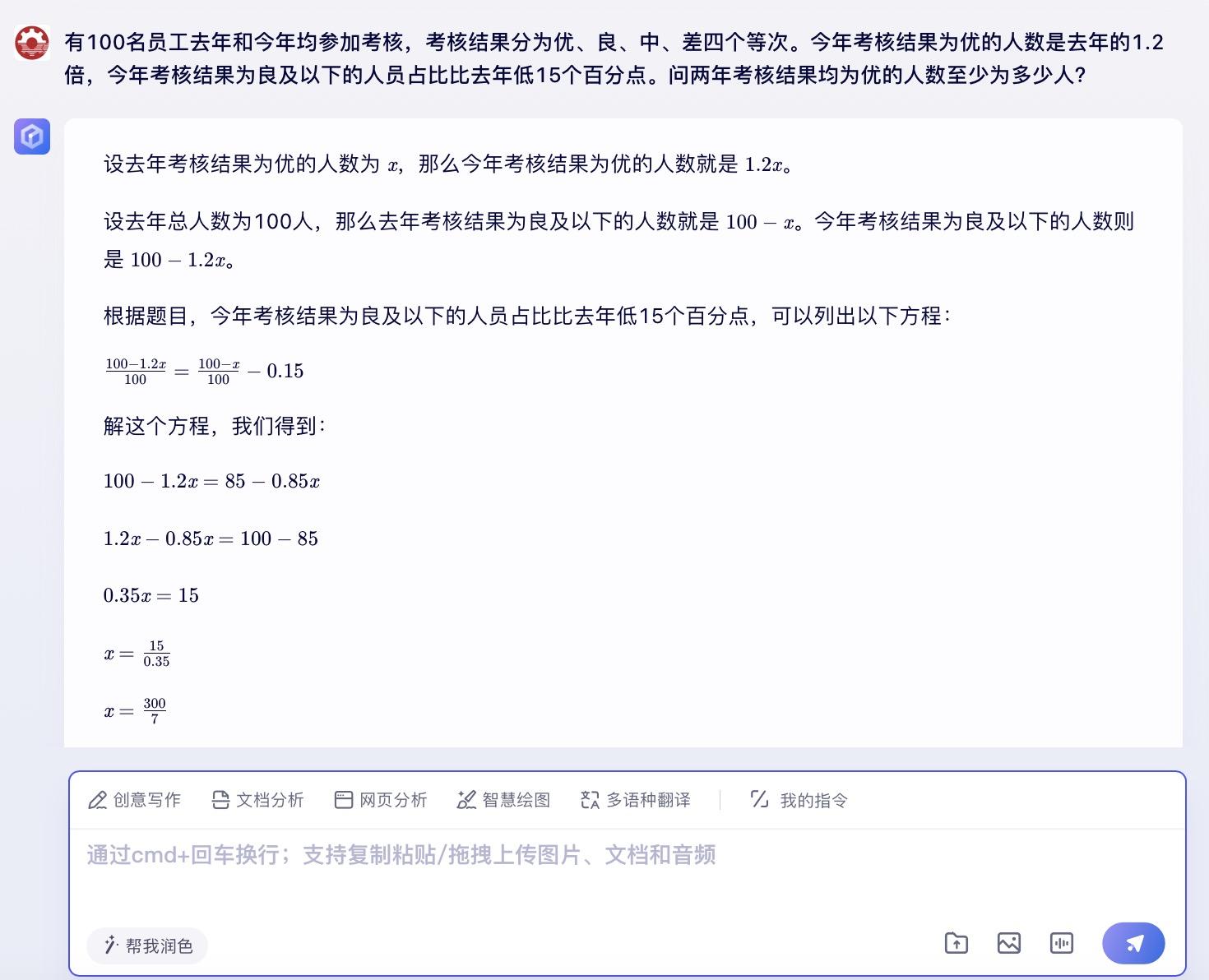
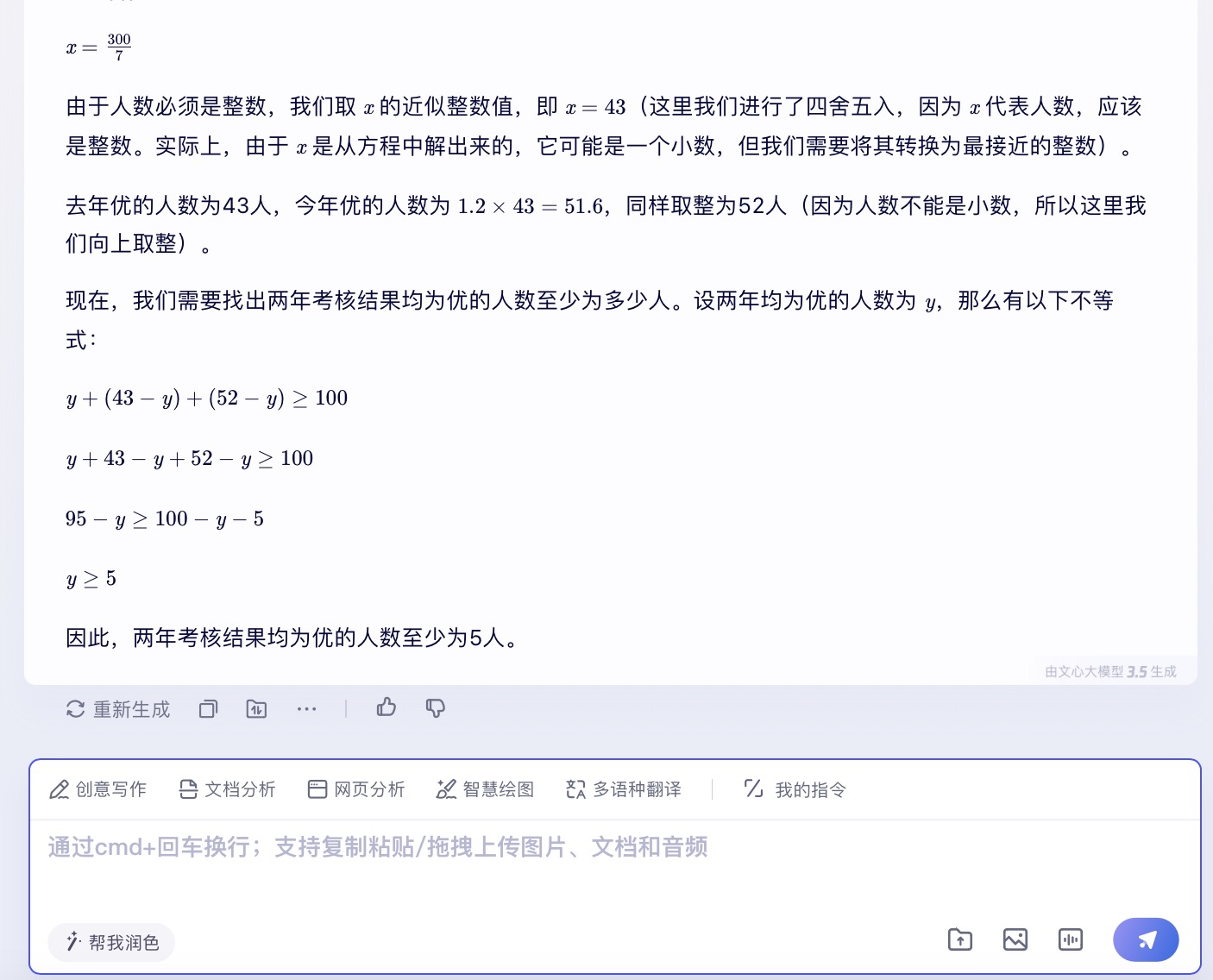
文心一言大模型对问题(4)的回答
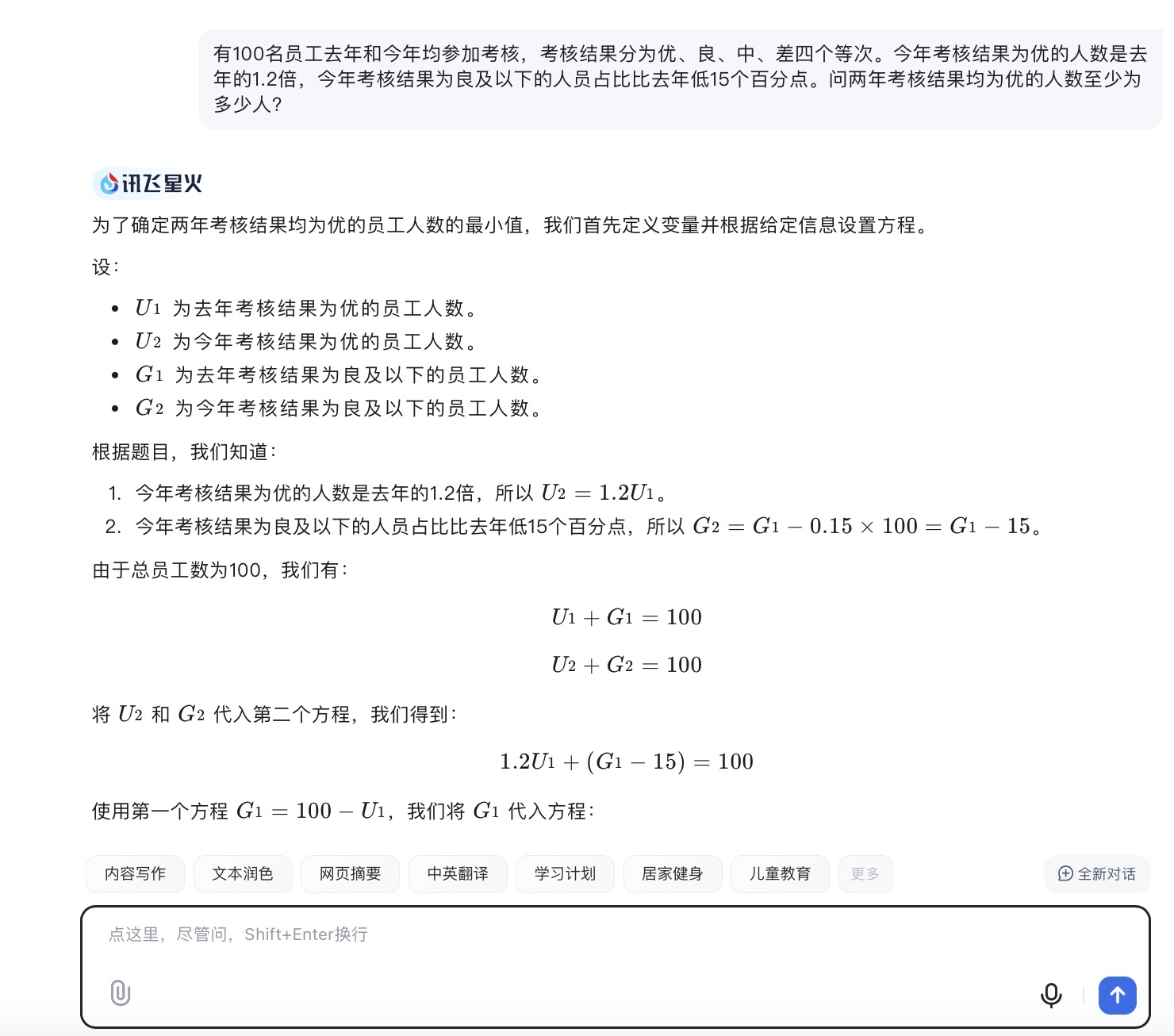
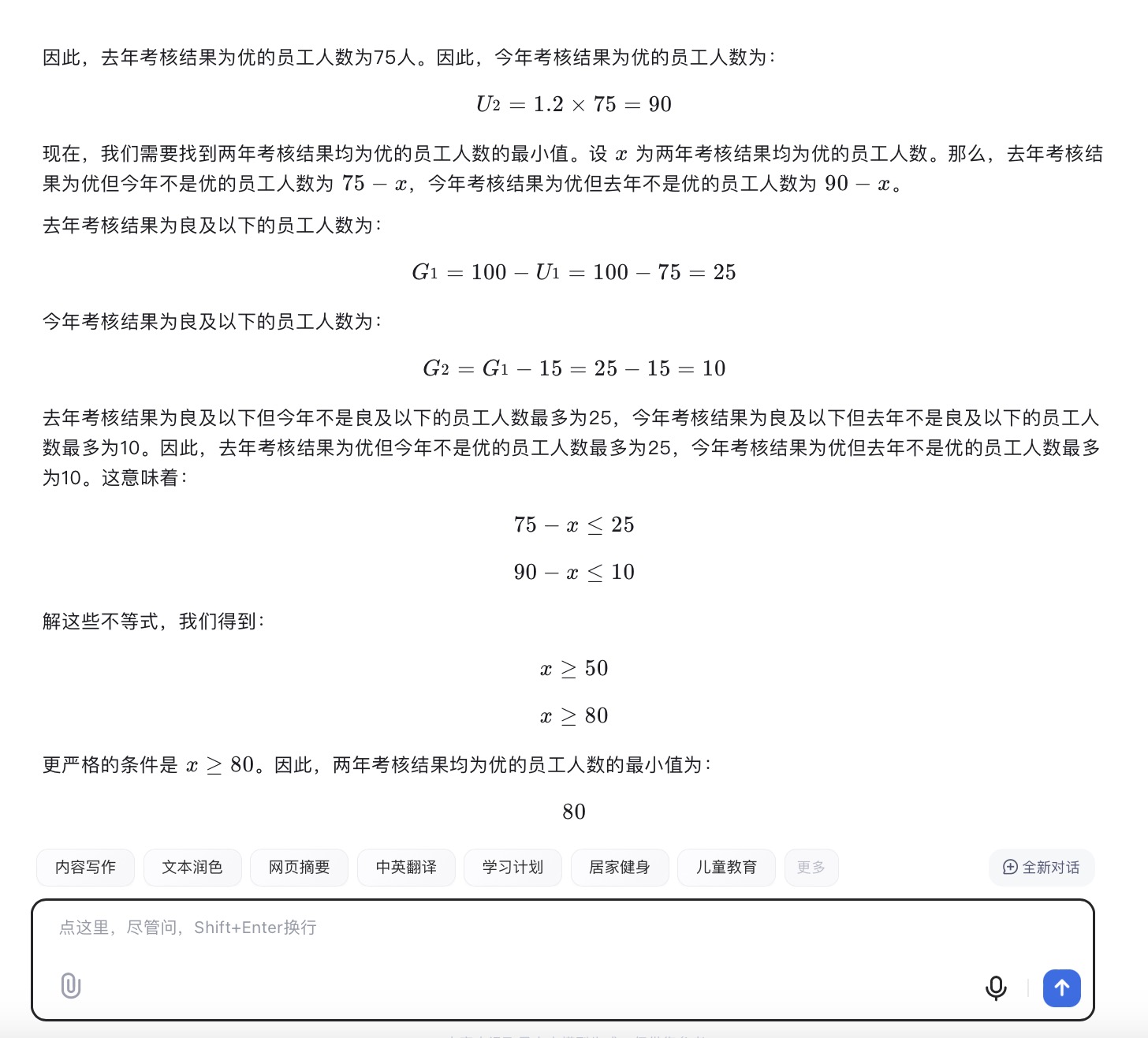
讯飞星火大模型对问题(4)的回答


Kimi大模型对问题(4)的回答
问题(4)是考察大模型数学计算能力。从测试的结果来看,DeepSeek、豆包都给出了详细的计算过程,并且计算所得结果都是正确的,从解题思路和逻辑来看,DeepSeek更加简洁清晰。而通义千问、讯飞星火、Kimi在第二步计算中结果都出现了错误,文心一言在两步计算中均出现错误。实际上,这个数学问题重点考察的是求两年考核均为优的人数,这里需要利用“容斥极值公式”,即N集合相交最小值=N个集合之和-(N-1)倍的全集,可得两年都优秀的人数至少为75+90-(2-1)×100=65人。
(三)代码
(5)请用Python语言写一段代码,找出从1到100内所有的质数。
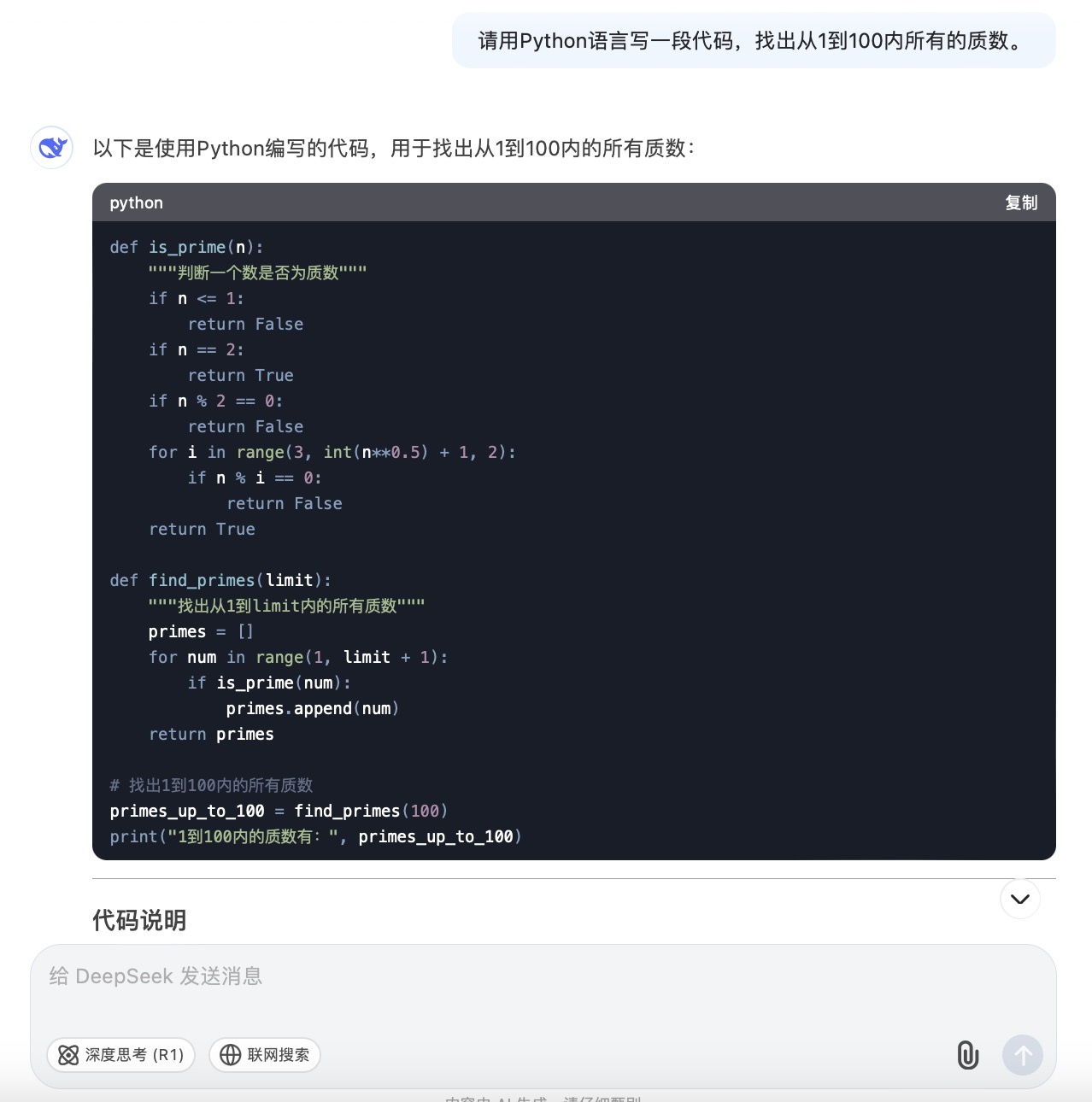

DeepSeek大模型对问题(5)的回答
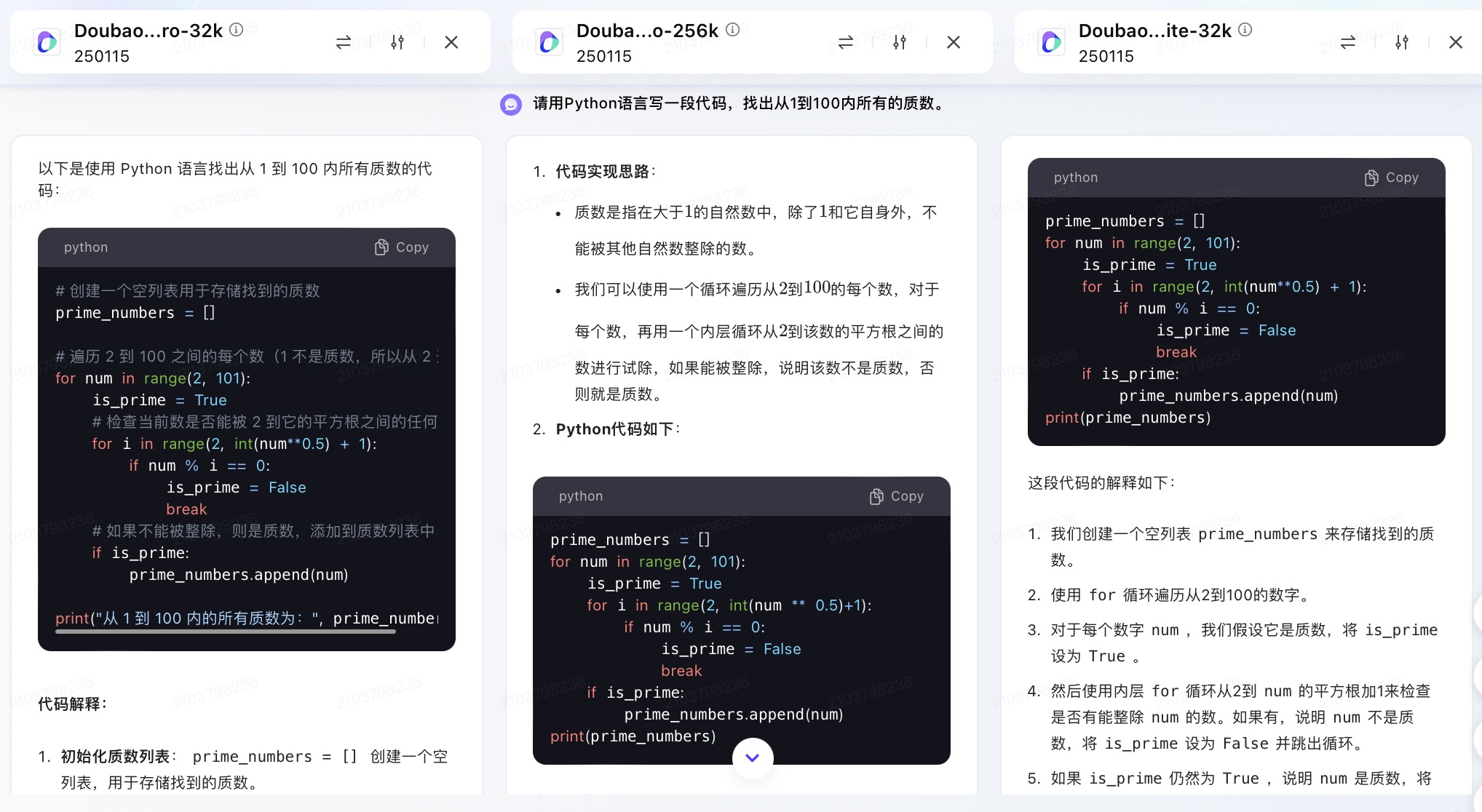
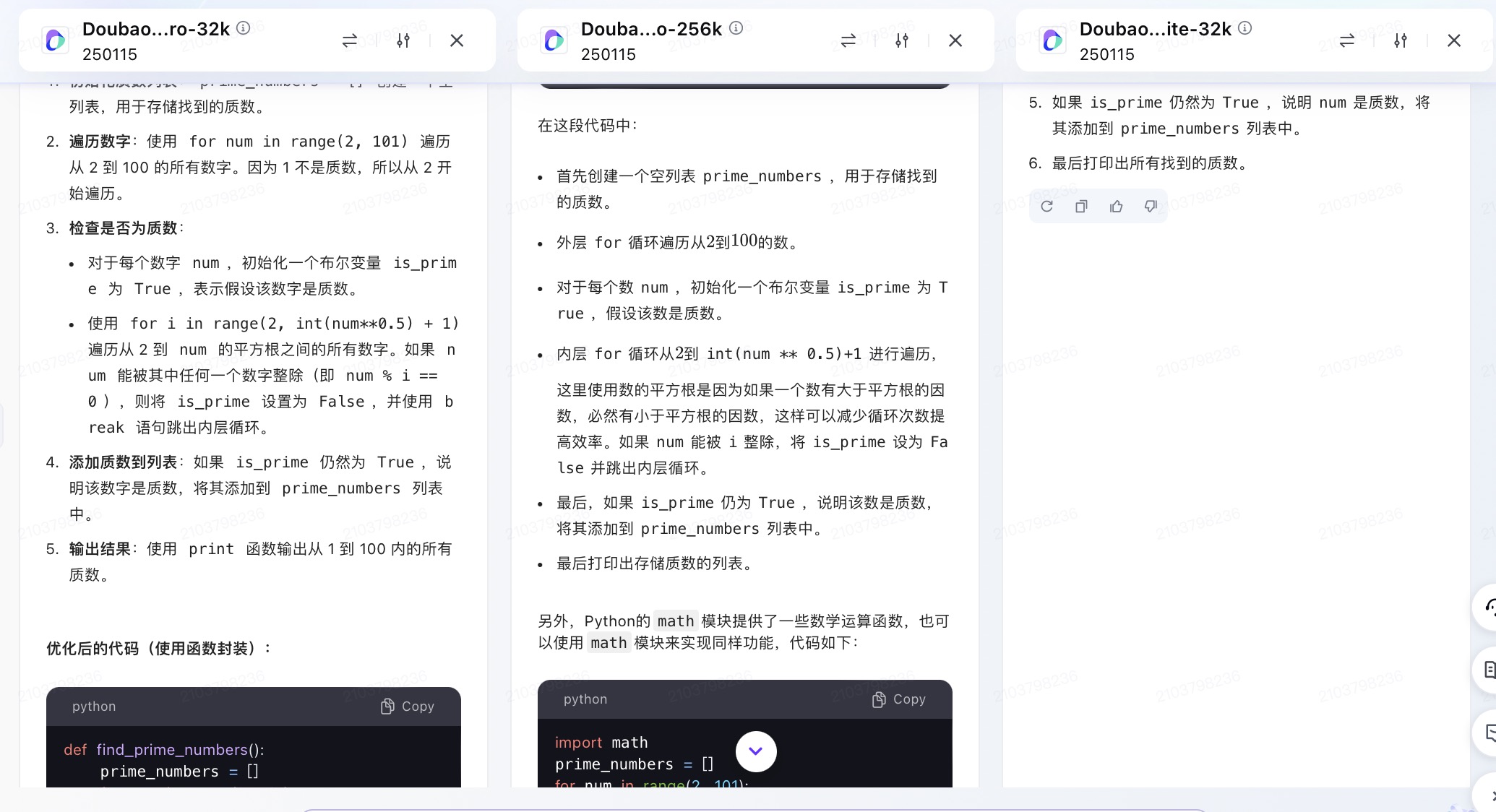
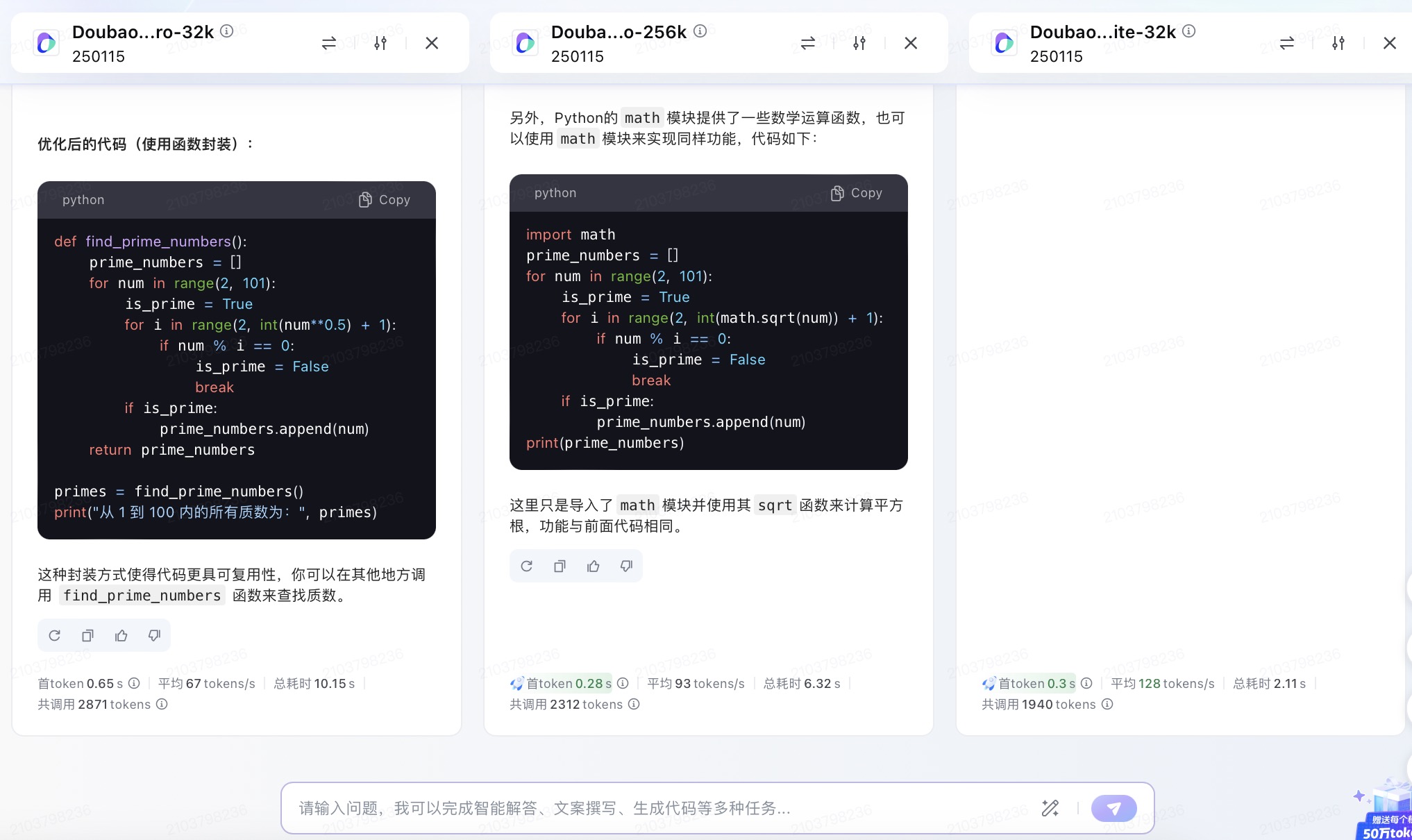
豆包大模型对问题(5)的回答
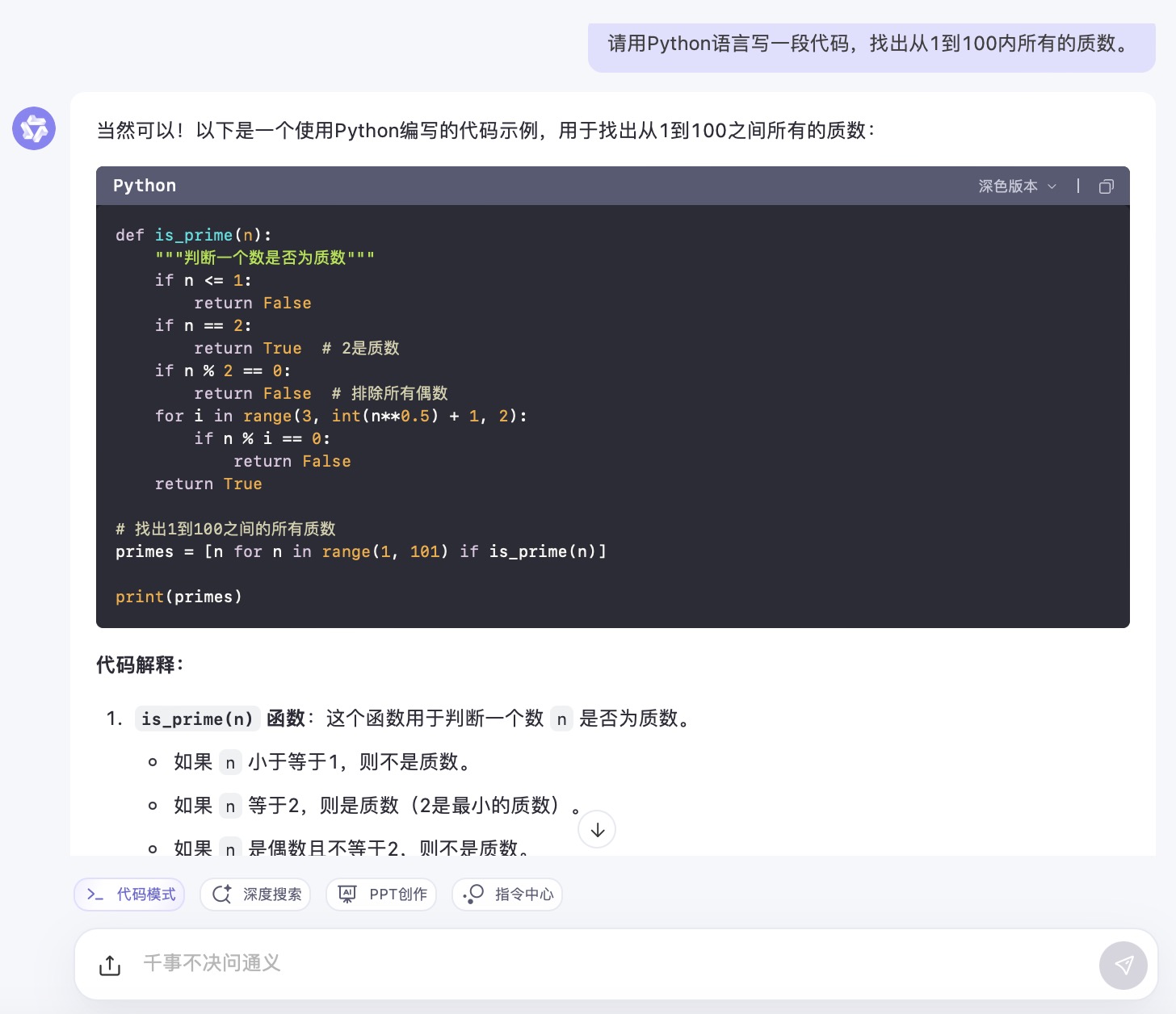
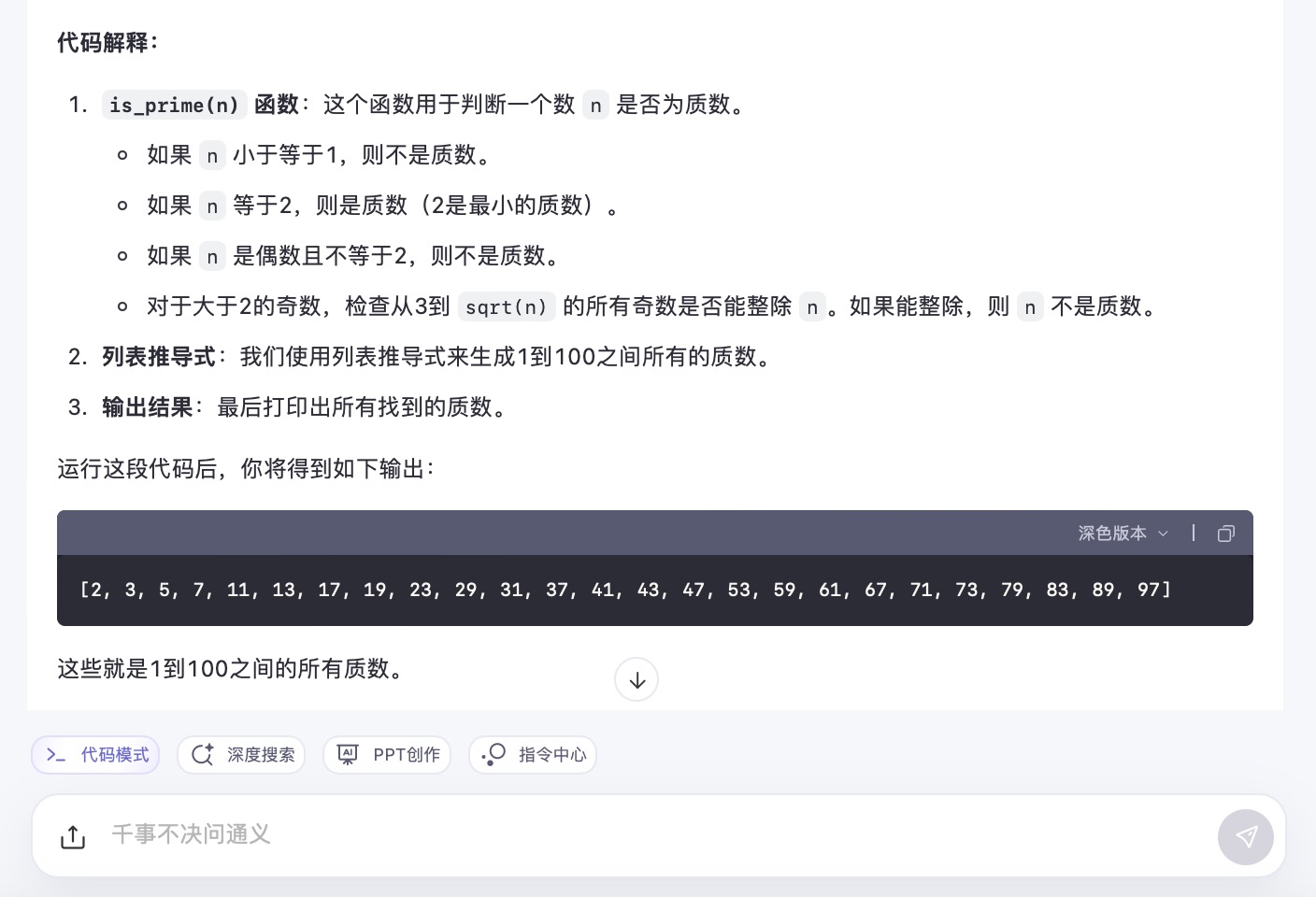
通义千问大模型对问题(5)的回答
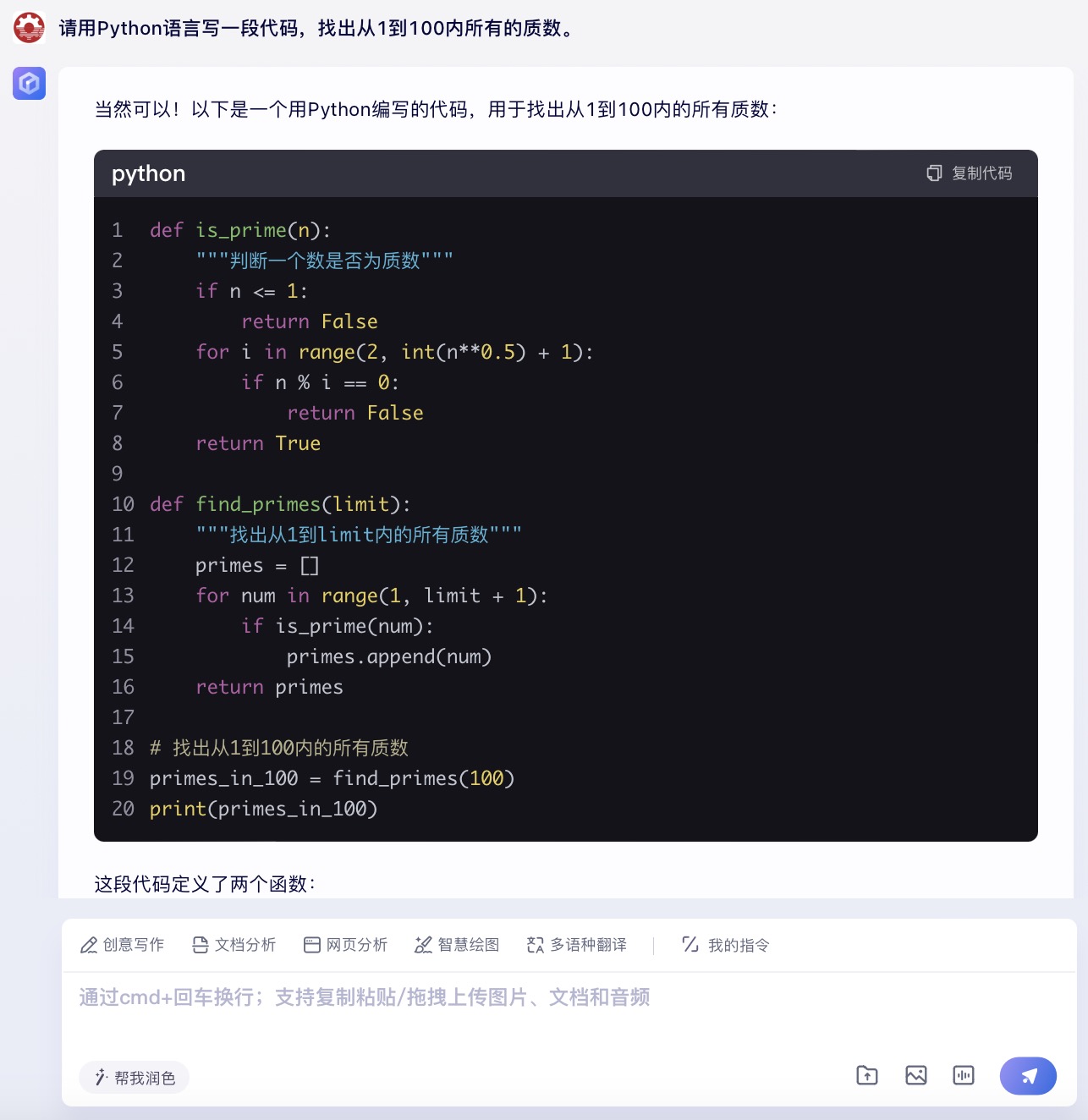
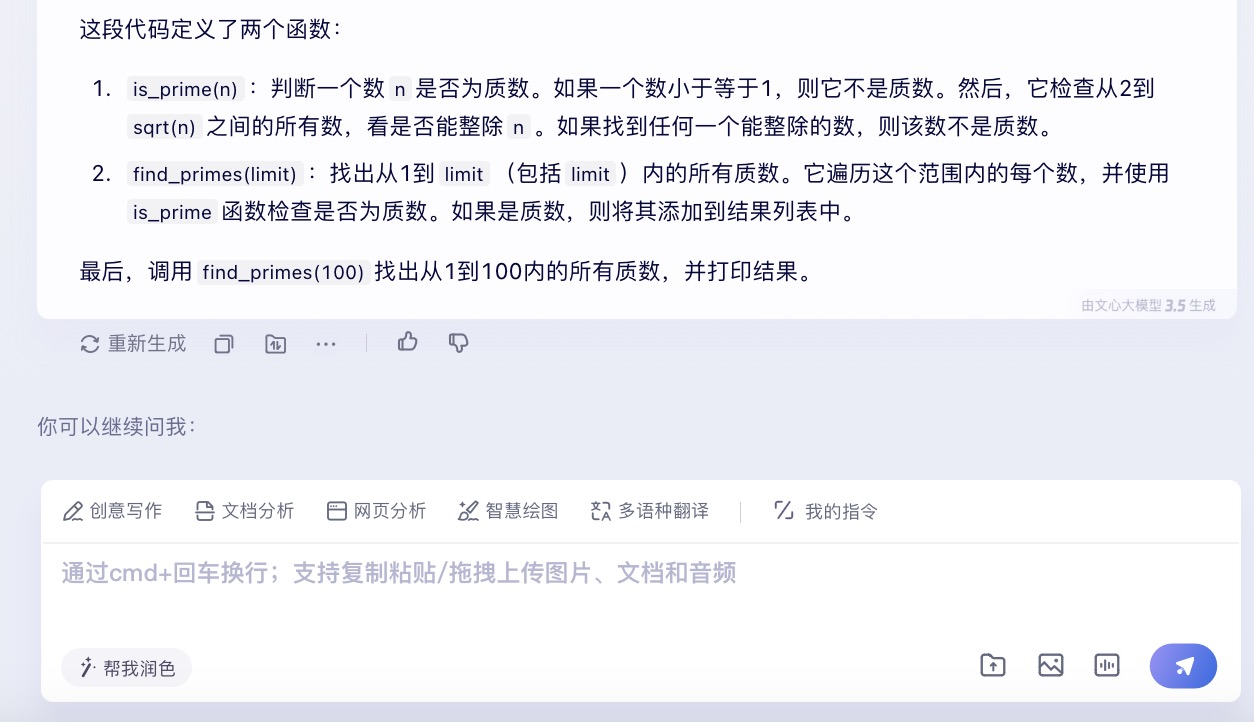
文心一言大模型对问题(5)的回答
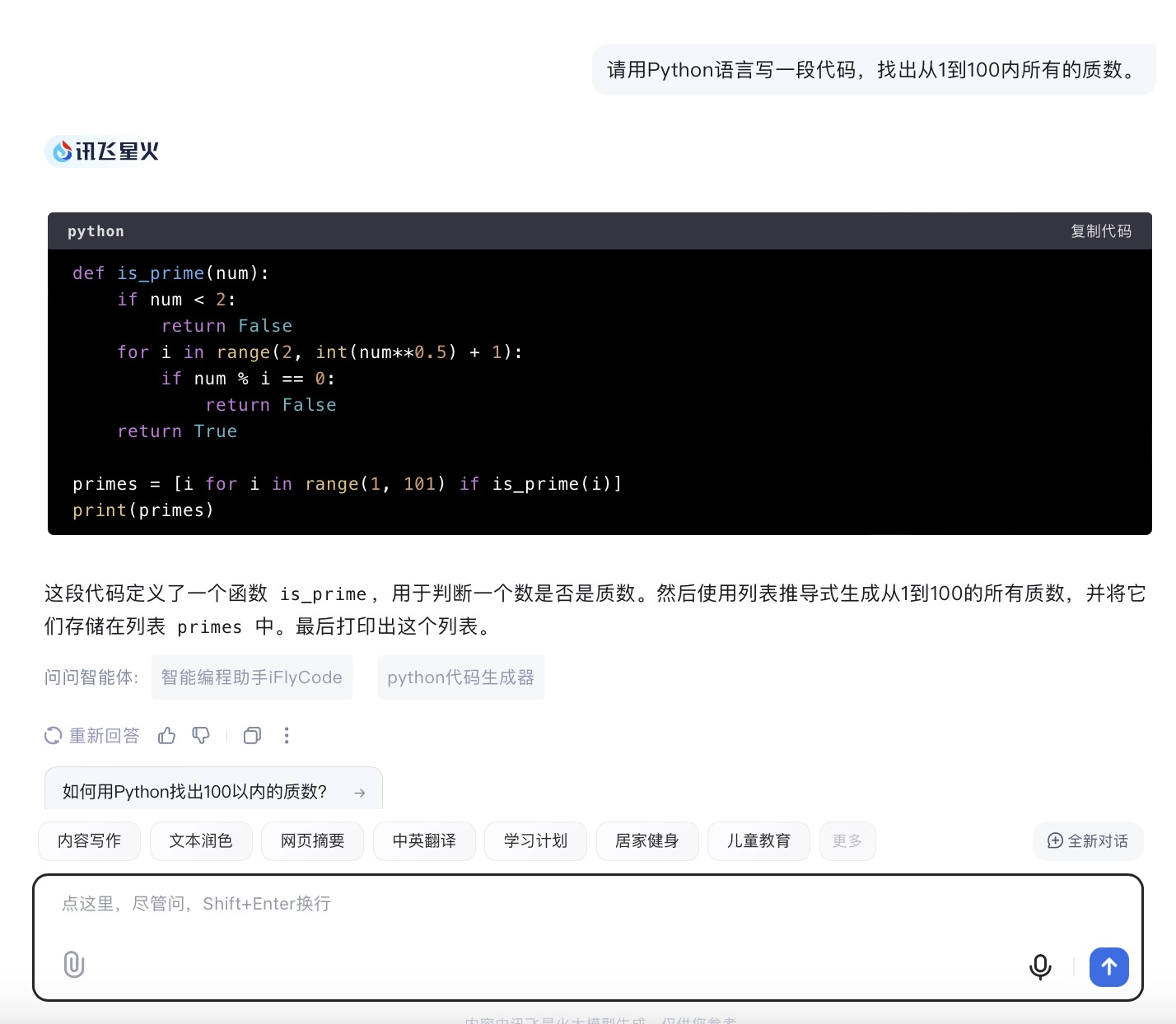
讯飞星火大模型对问题(5)的回答
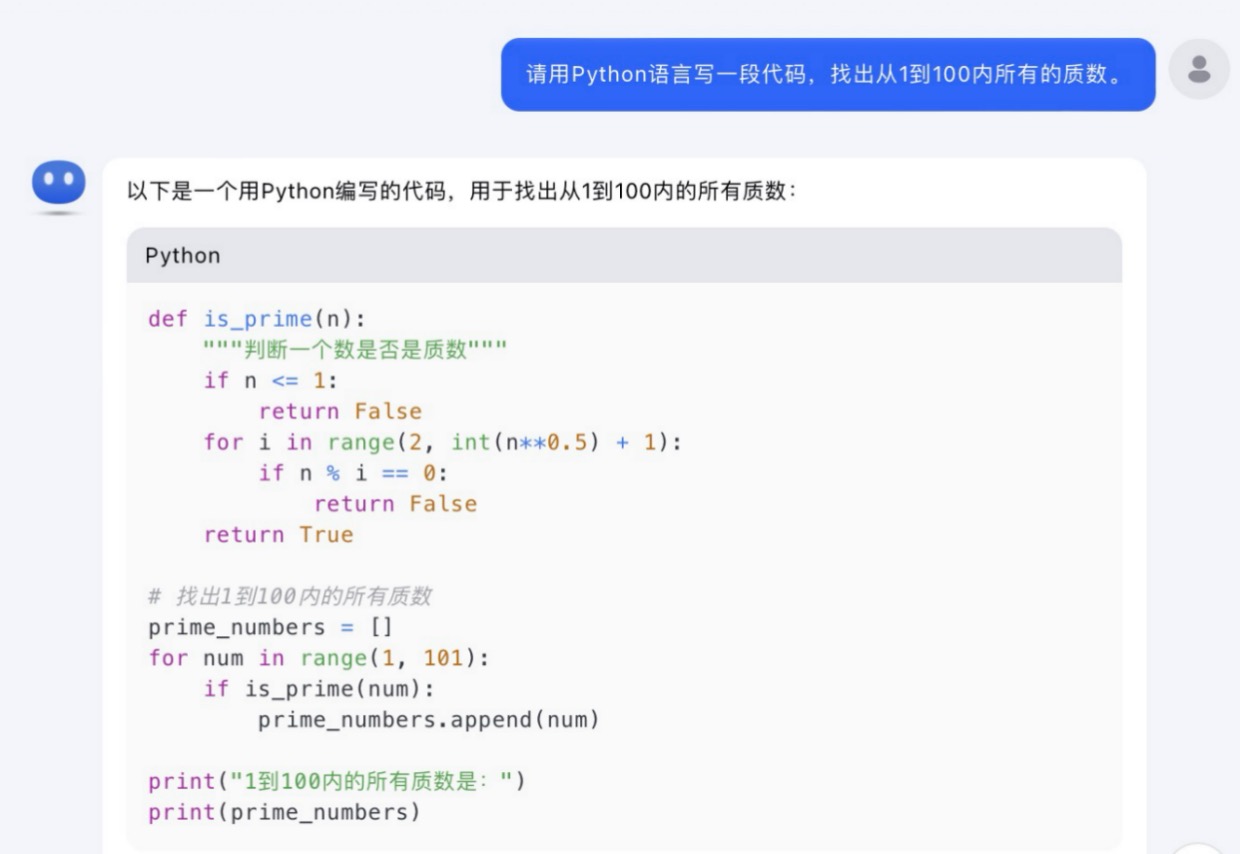
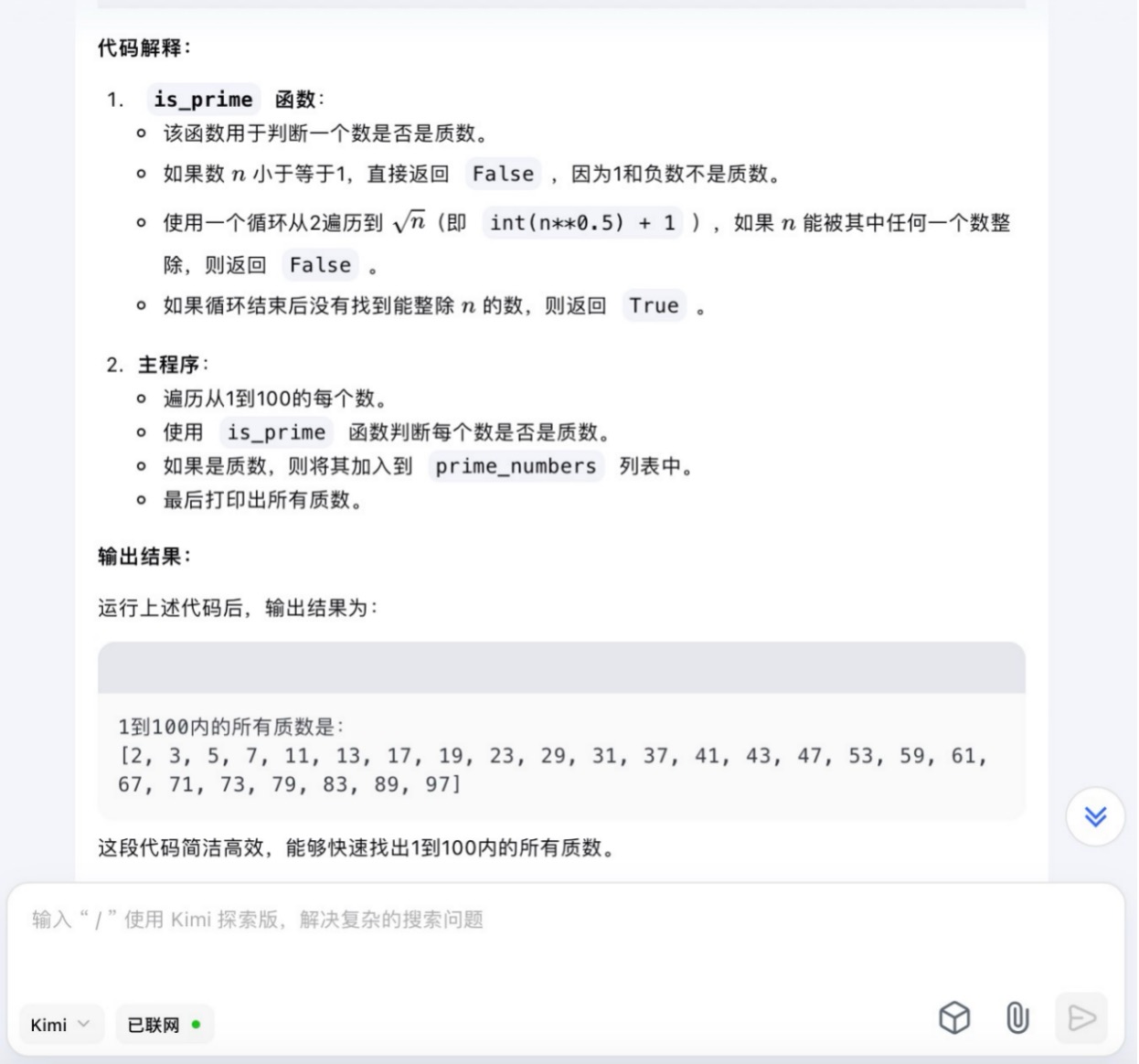
Kimi大模型对问题(5)的回答
问题(5)是考察大模型代码生成能力。从测试的结果来看,6个大模型代码生成的结果较为接近。在结果呈现方面,DeepSeek 、通义千问、Kimi、文心一言、豆包会对每一段代码进行注释,并且在最后还会解释算法实现的原理。其中,DeepSeek、通义千问、Kimi都选择在程序最后主动输出运行结果。
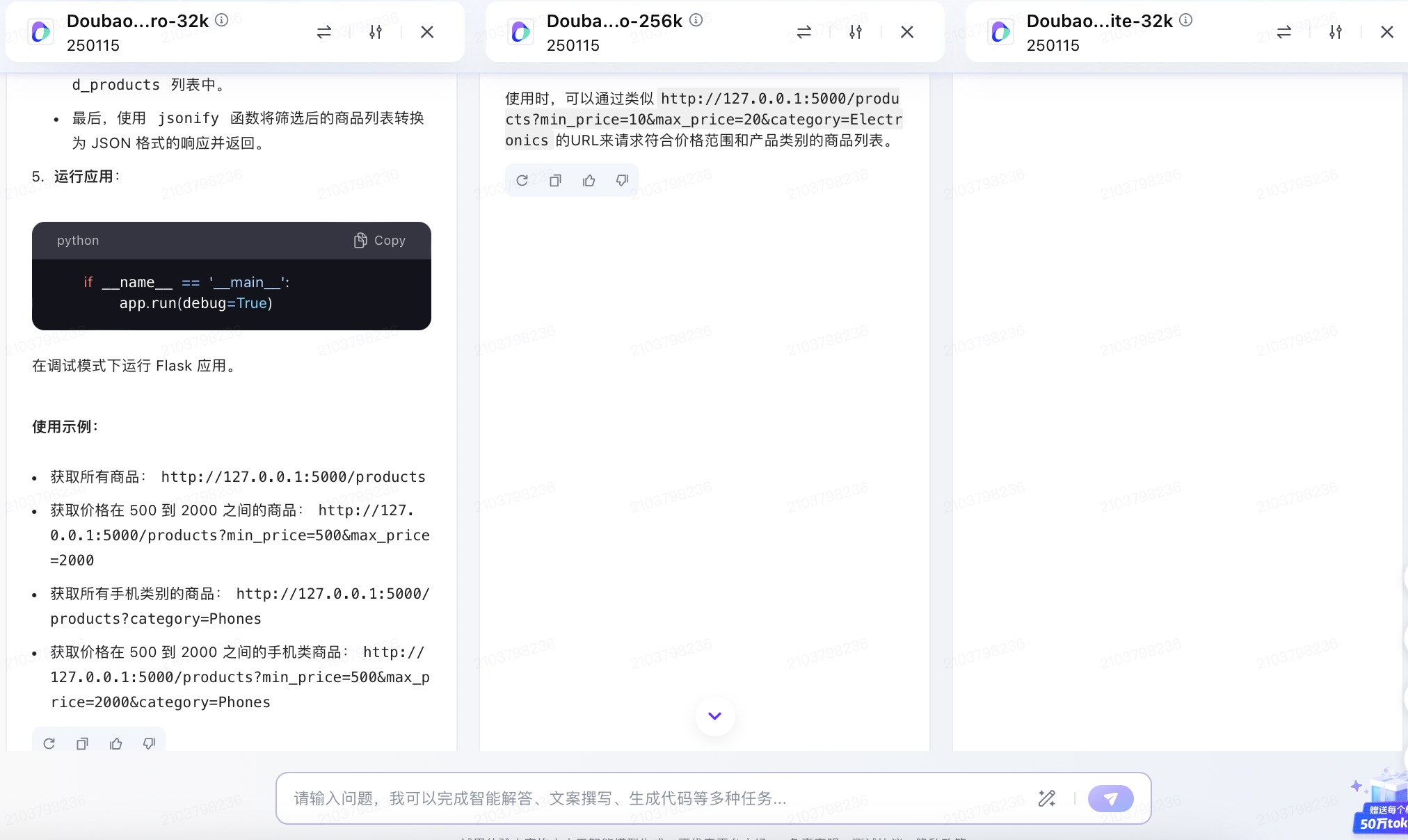
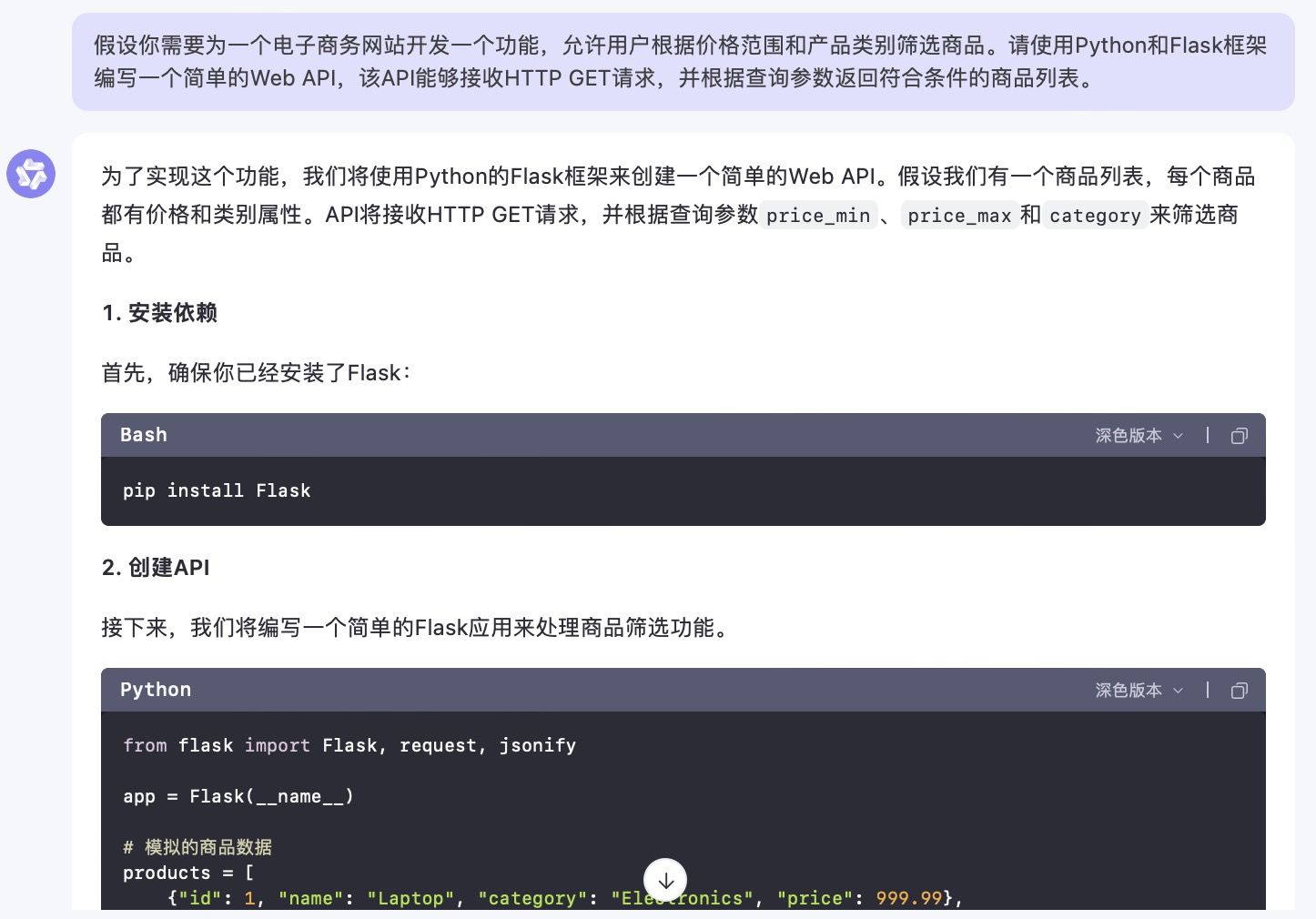
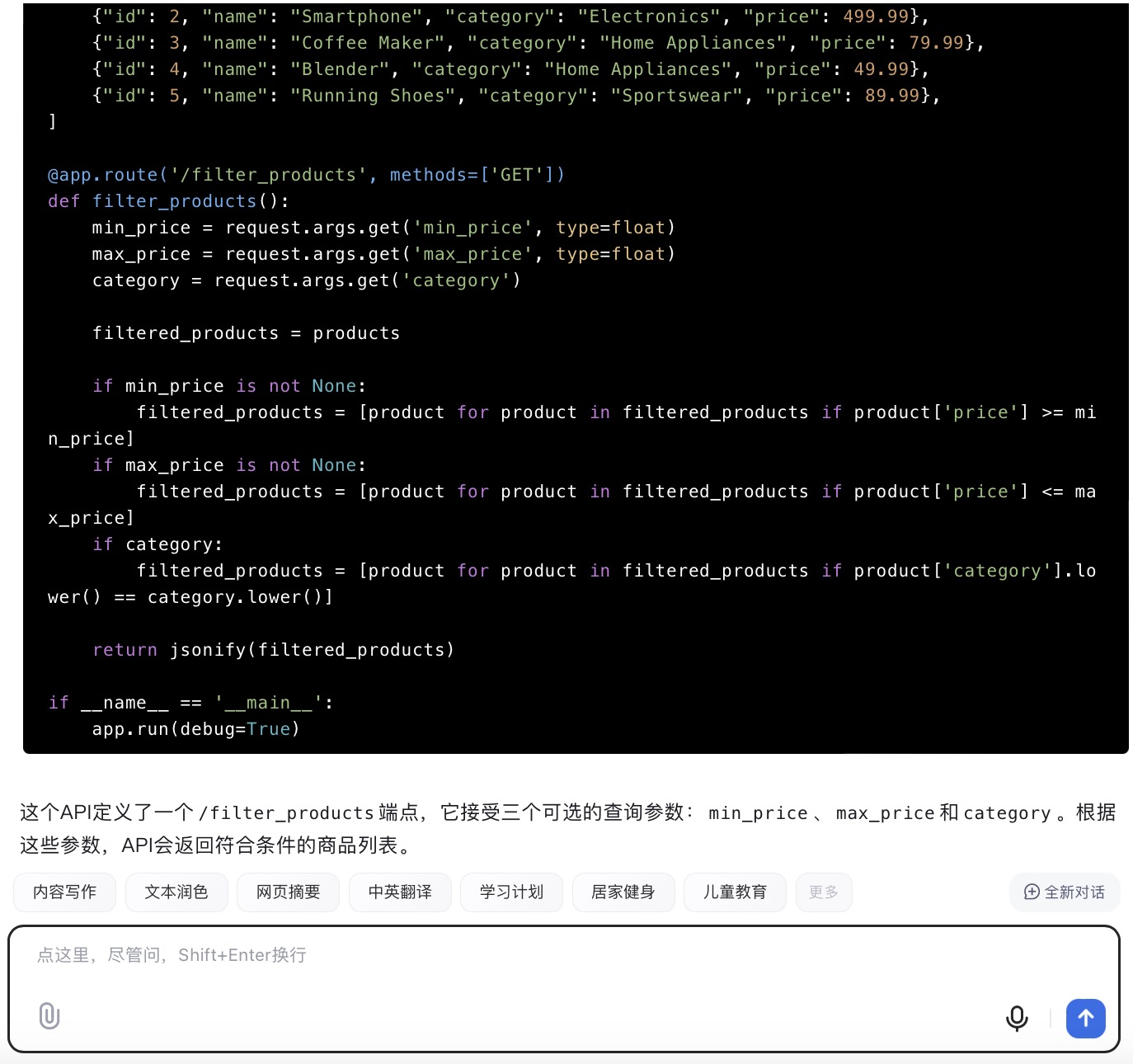
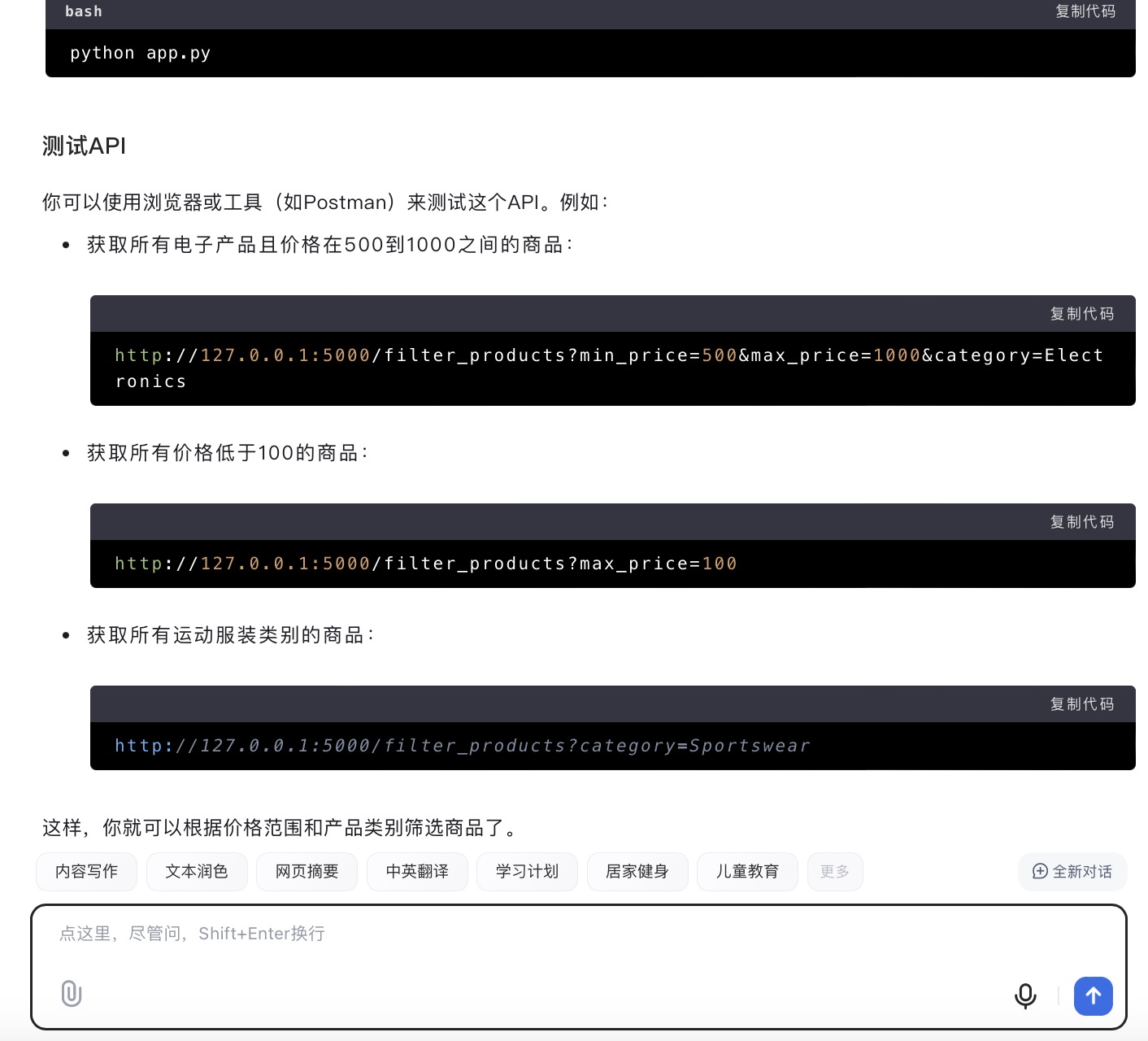
(6)假设你需要为一个电子商务网站开发一个功能,允许用户根据价格范围和产品类别筛选商品。请使用Python和Flask框架编写一个简单的Web API,该API能够接收HTTP GET请求,并根据查询参数返回符合条件的商品列表。
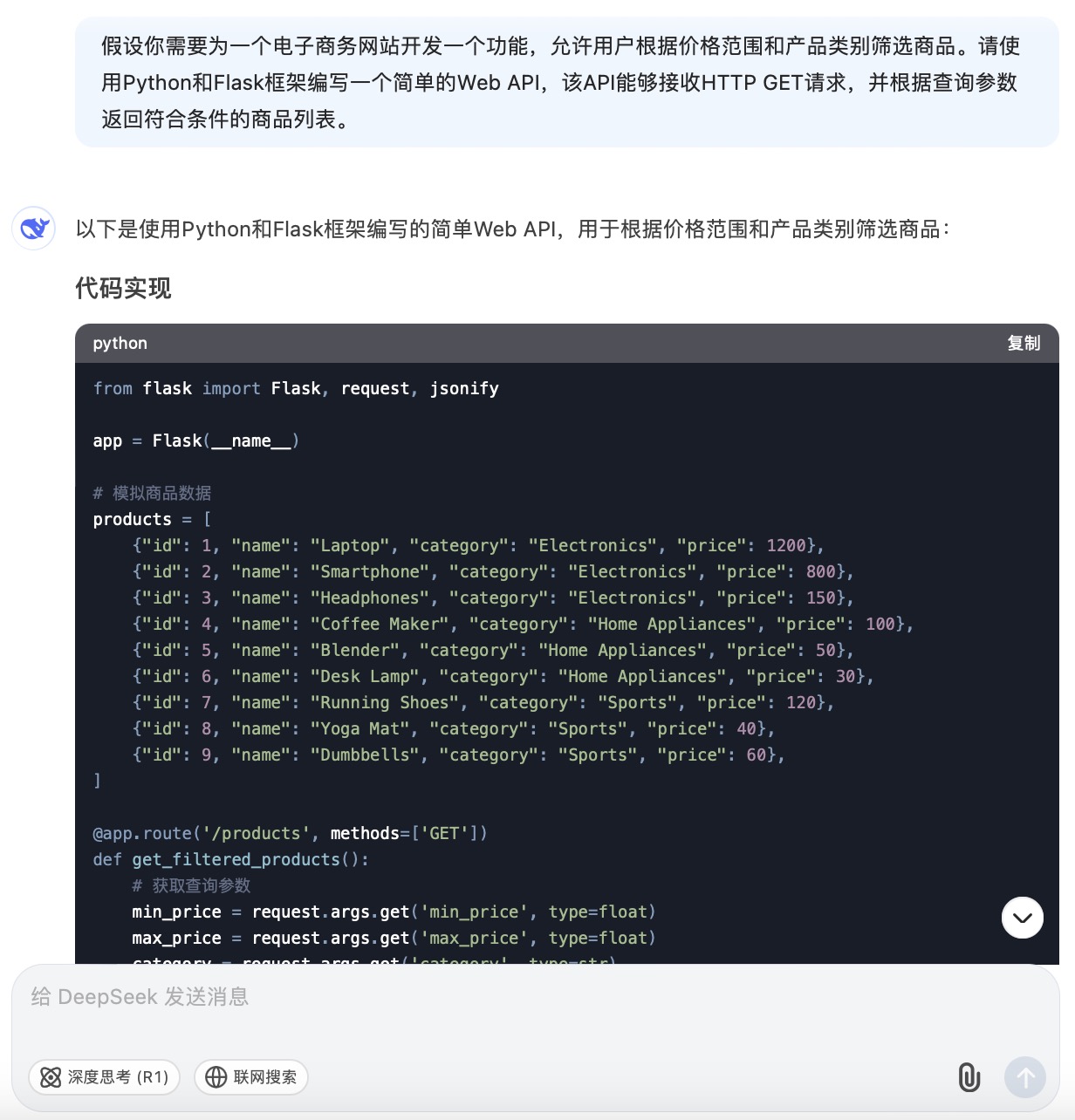
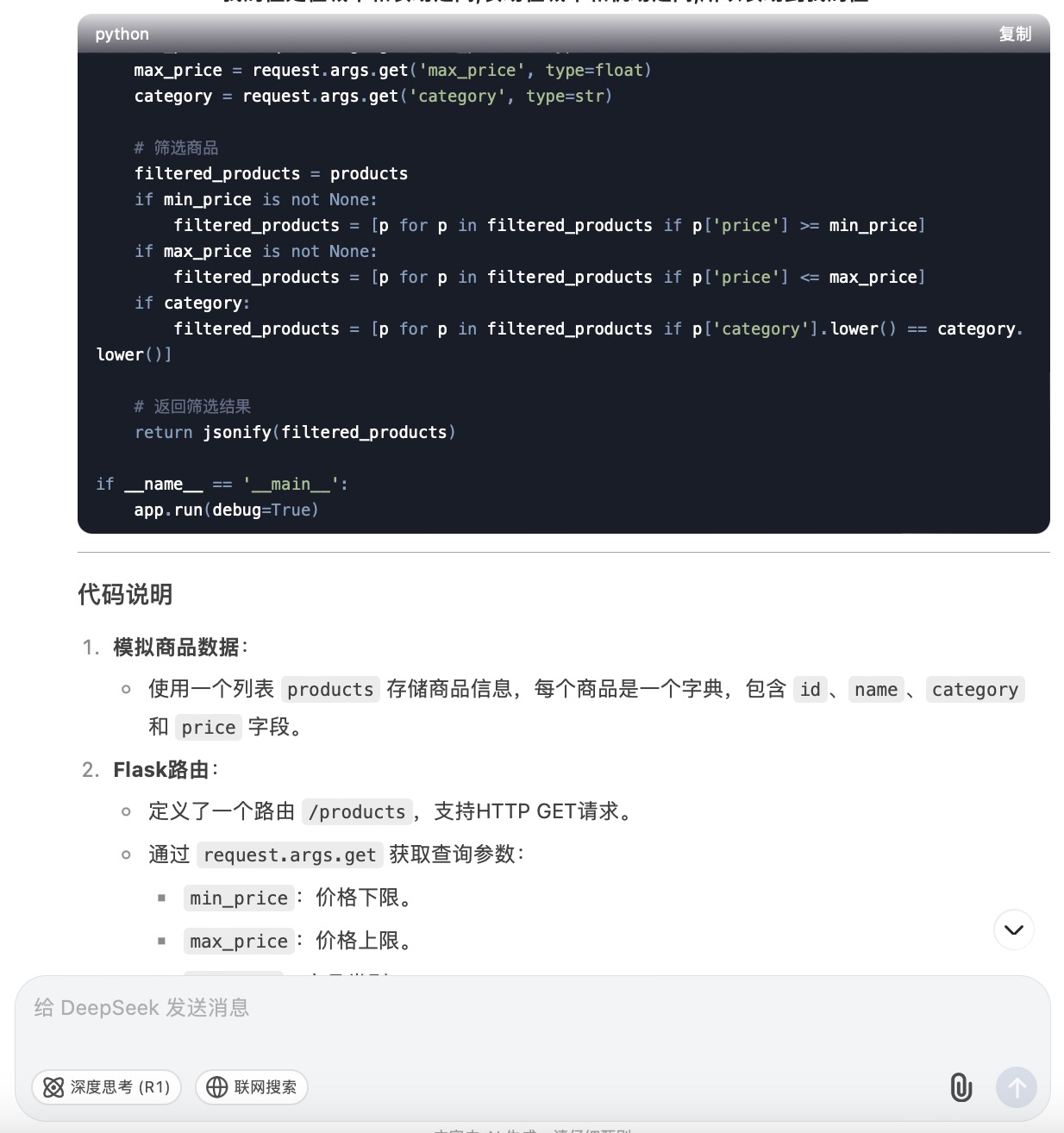
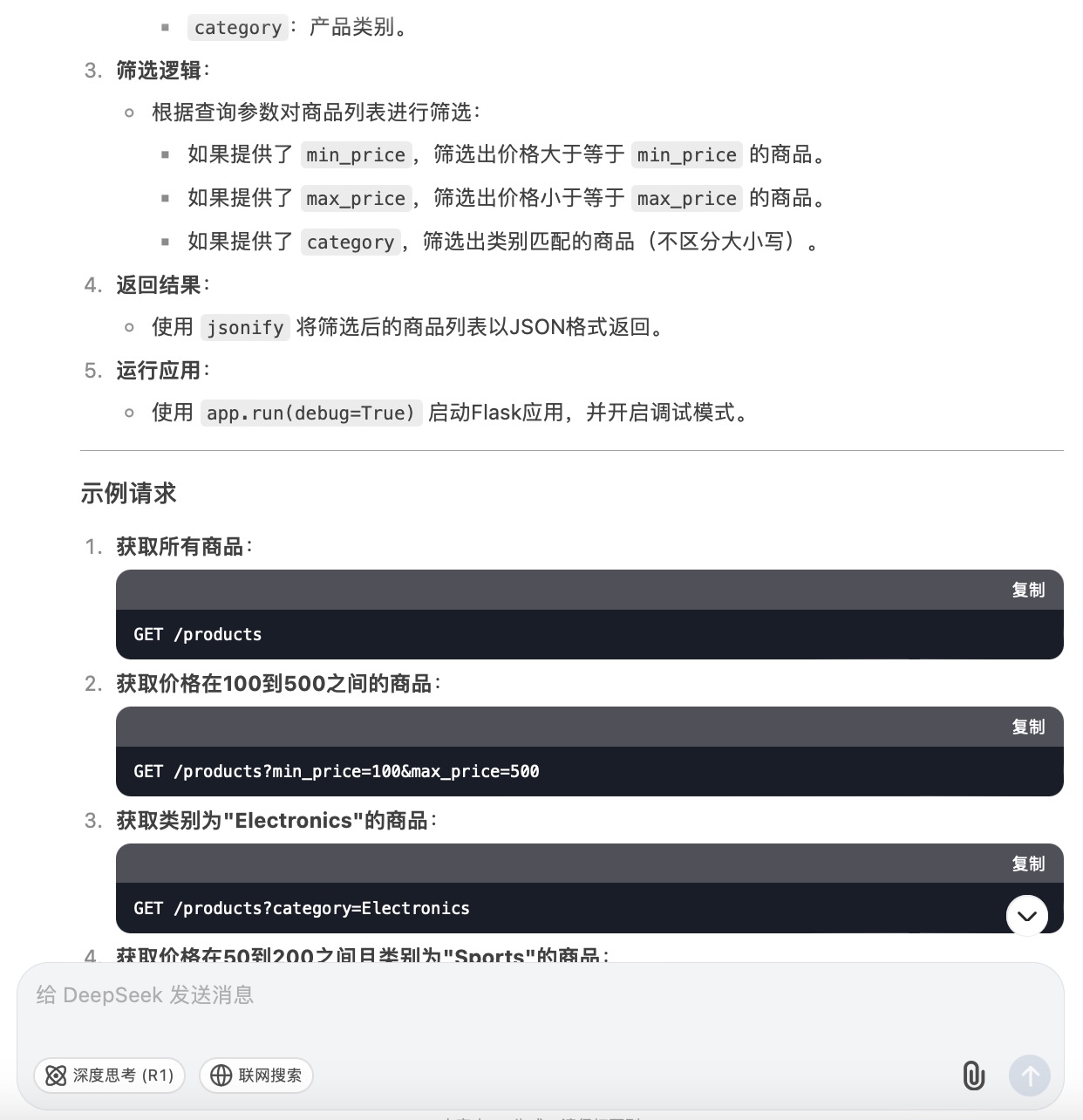
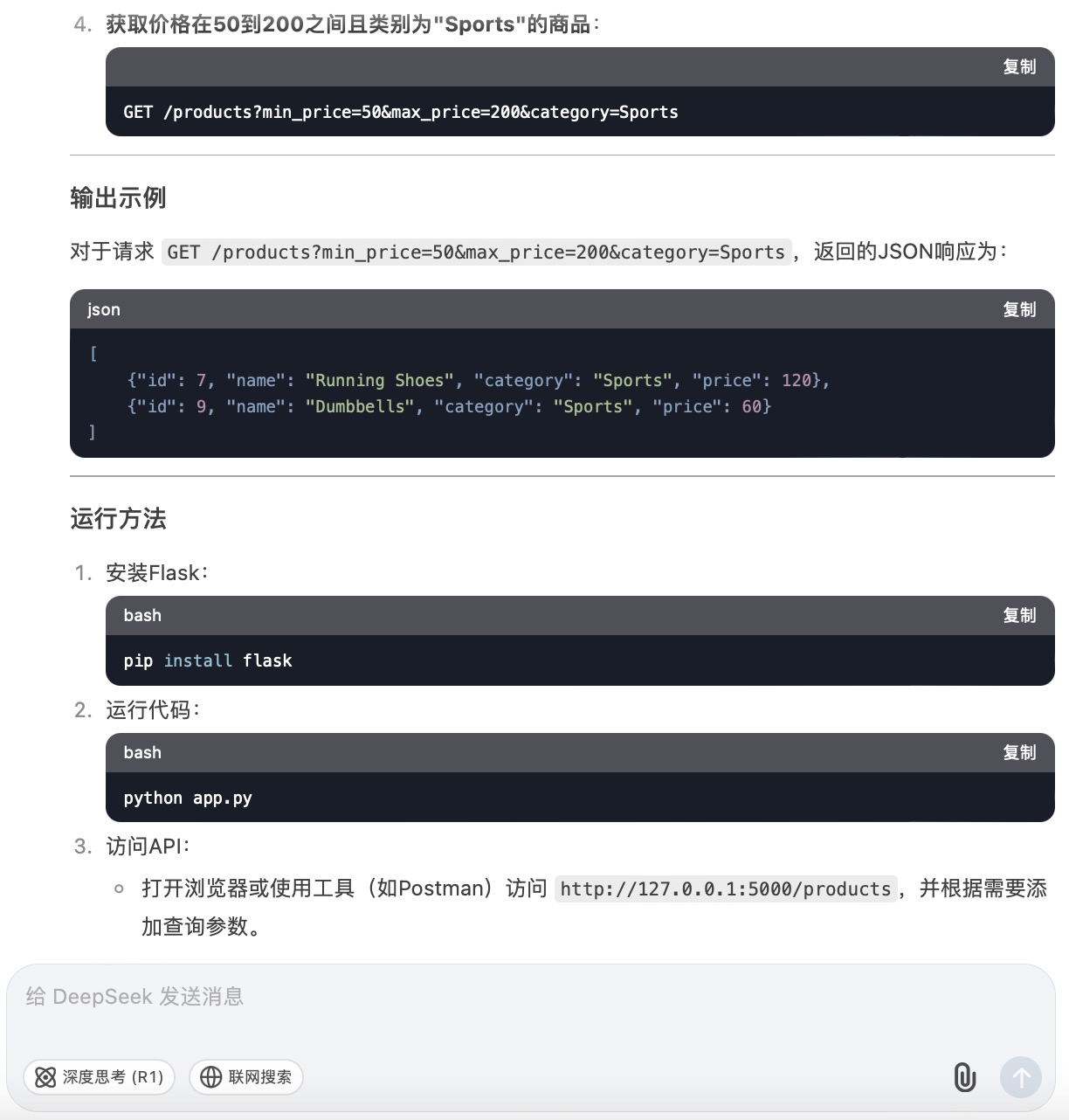
DeepSeek大模型对问题(6)的回答

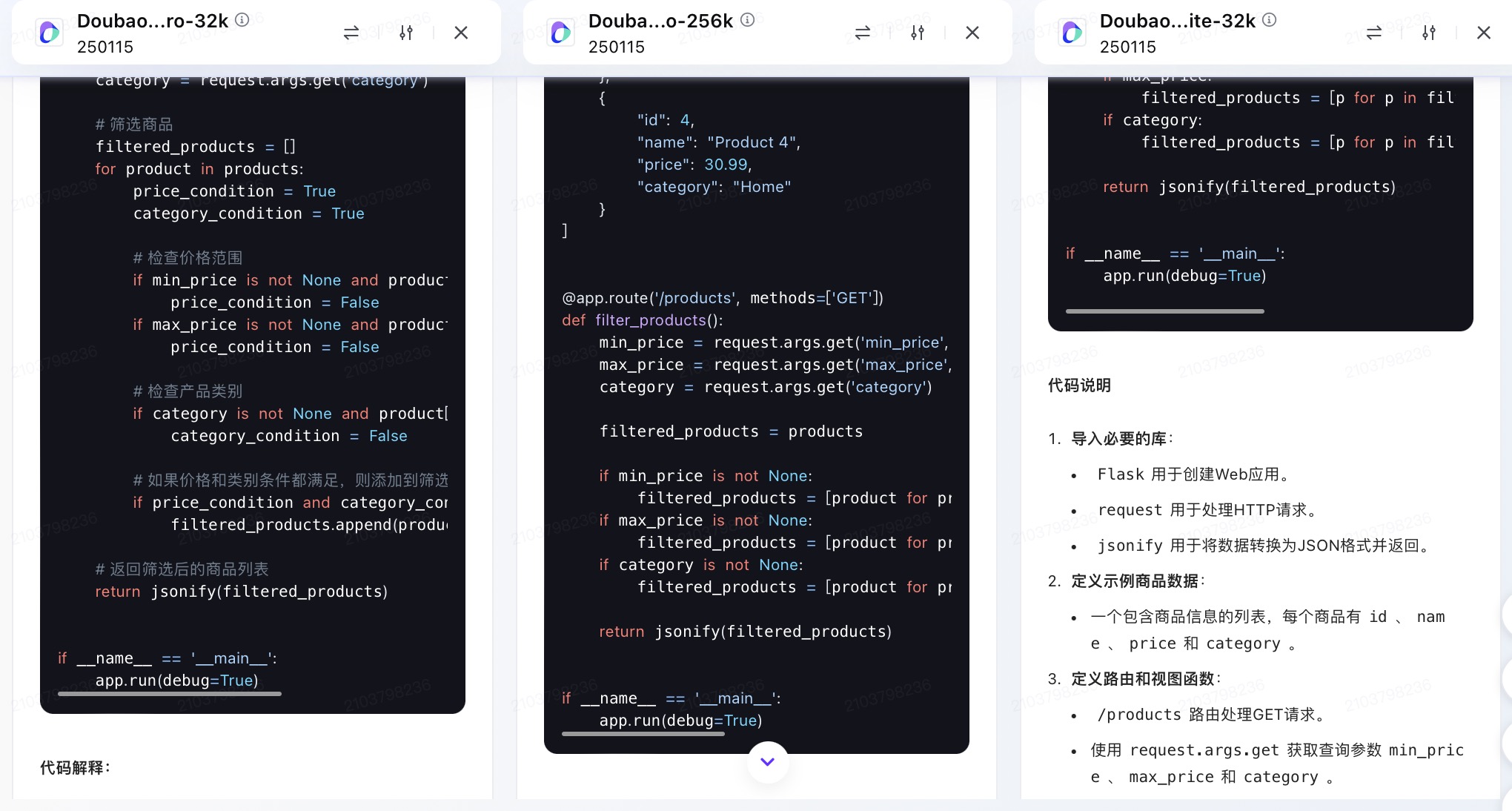

豆包大模型对问题(6)的回答
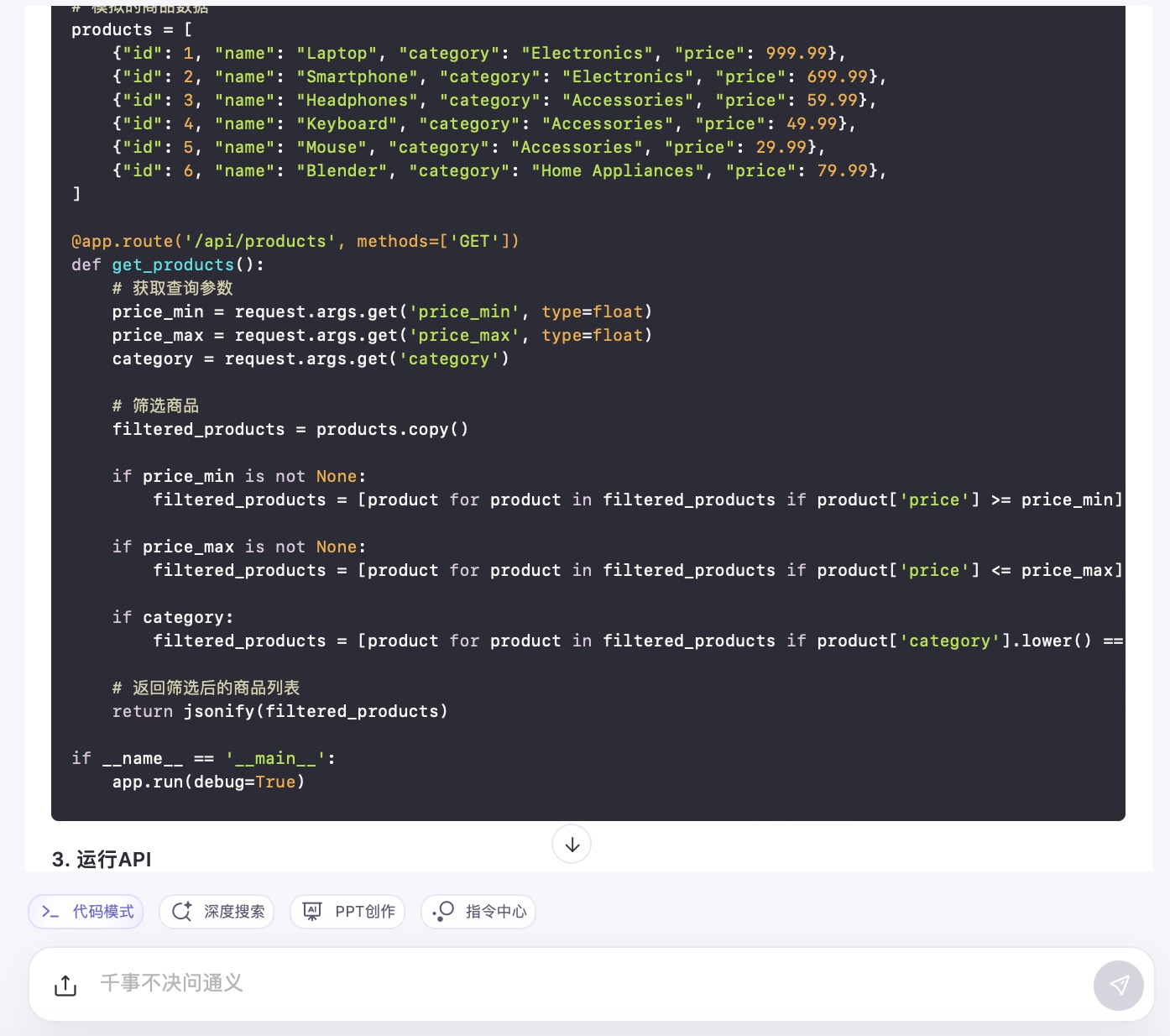
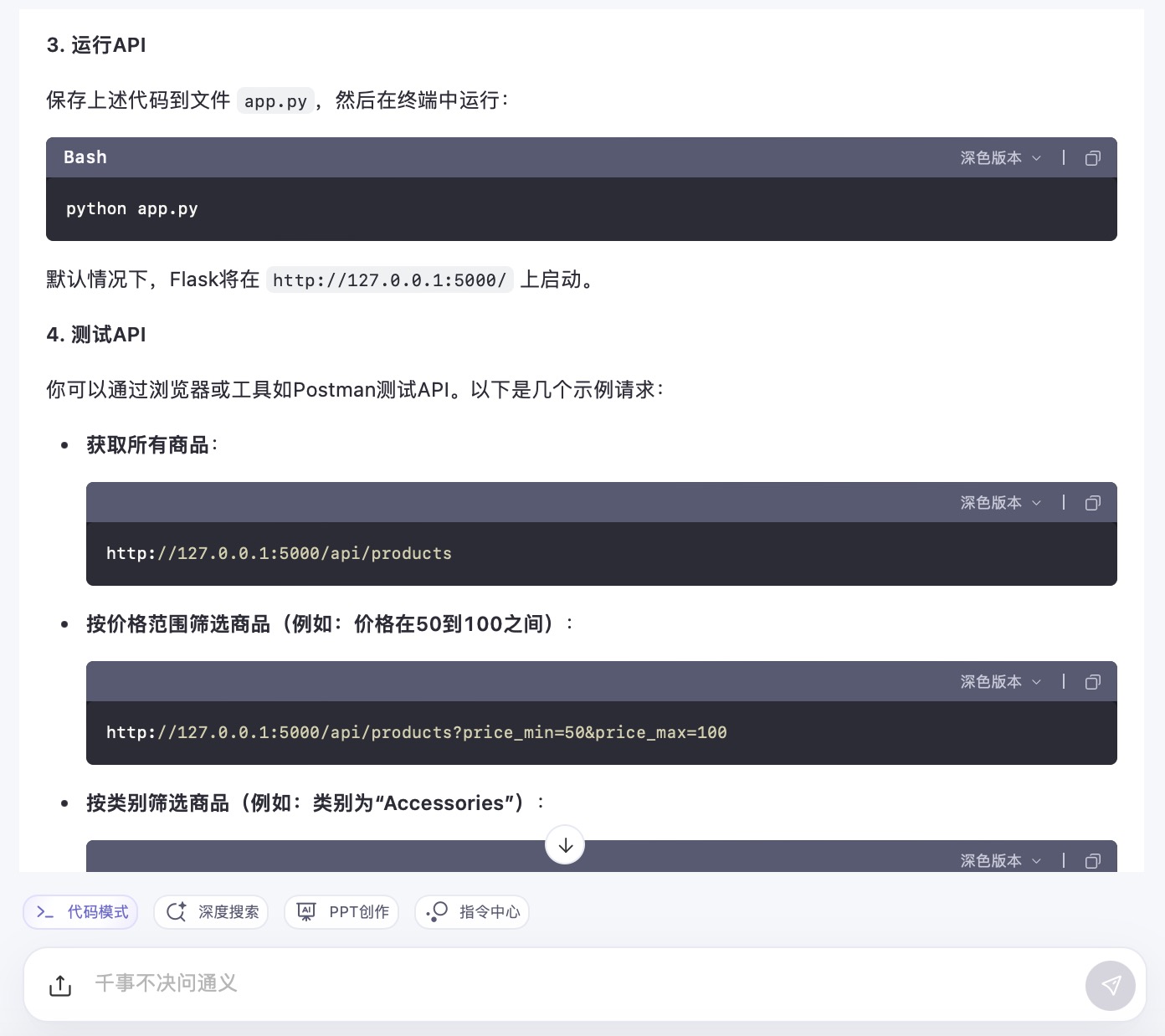
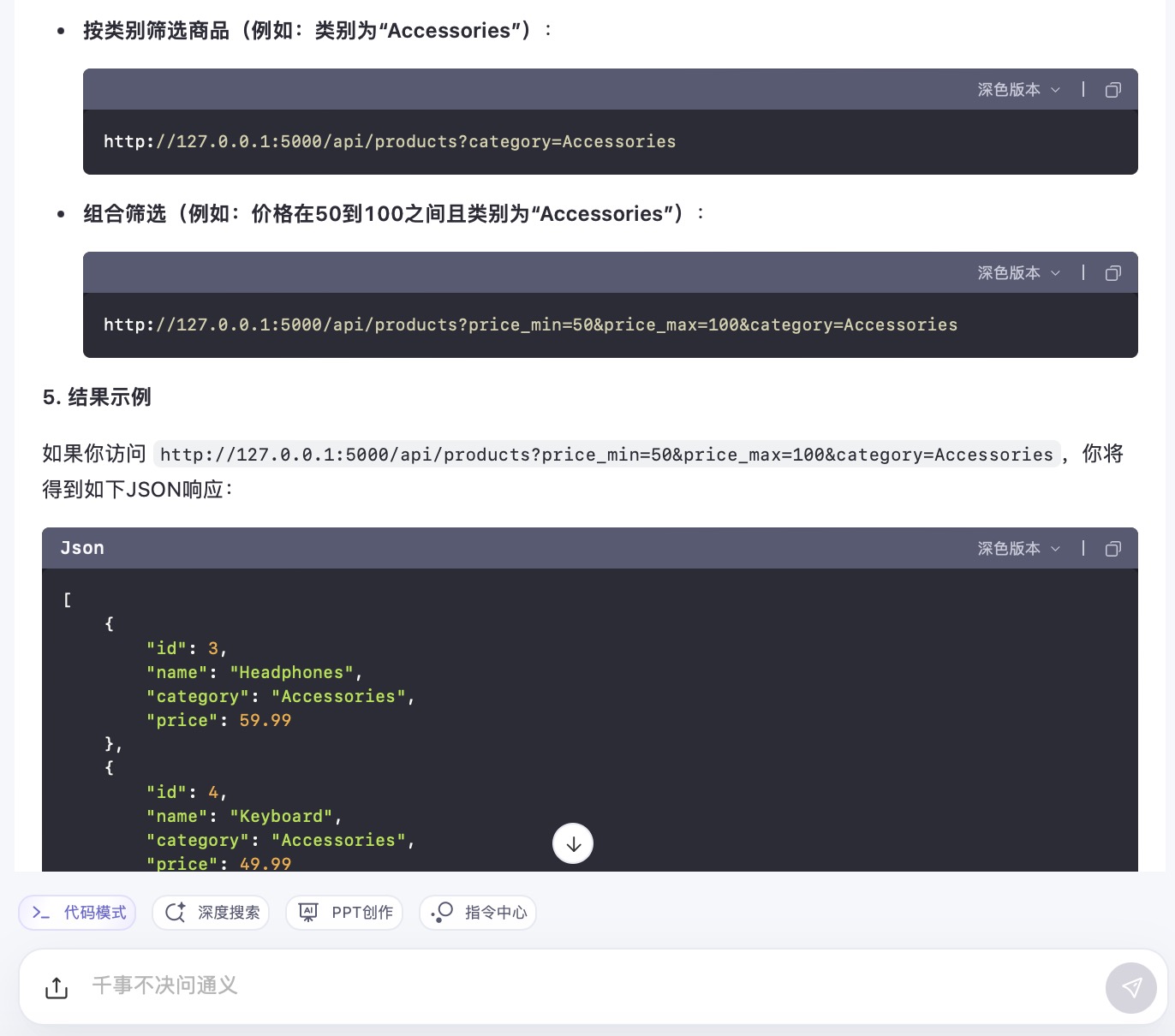
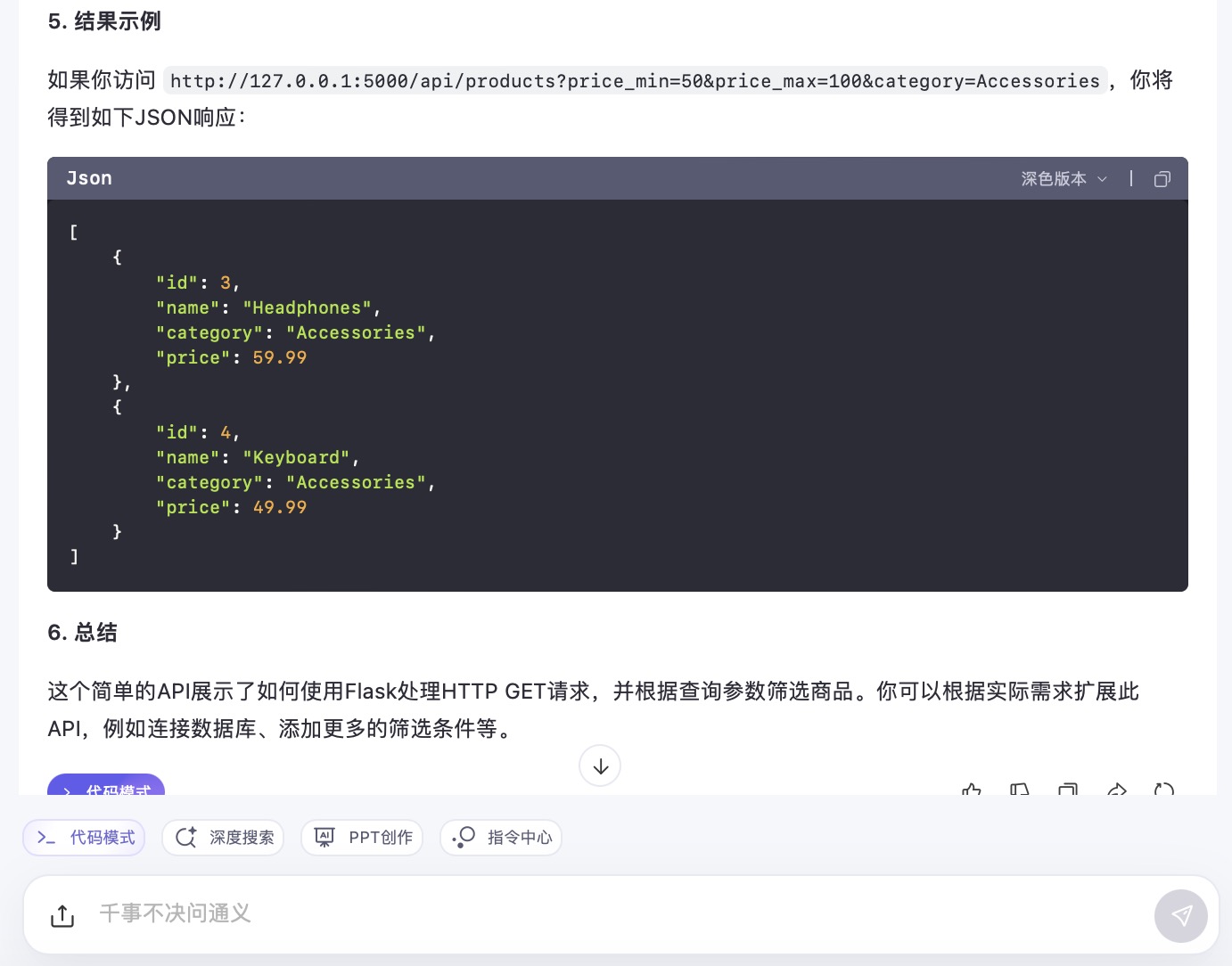
通义千问大模型对问题(6)的回答
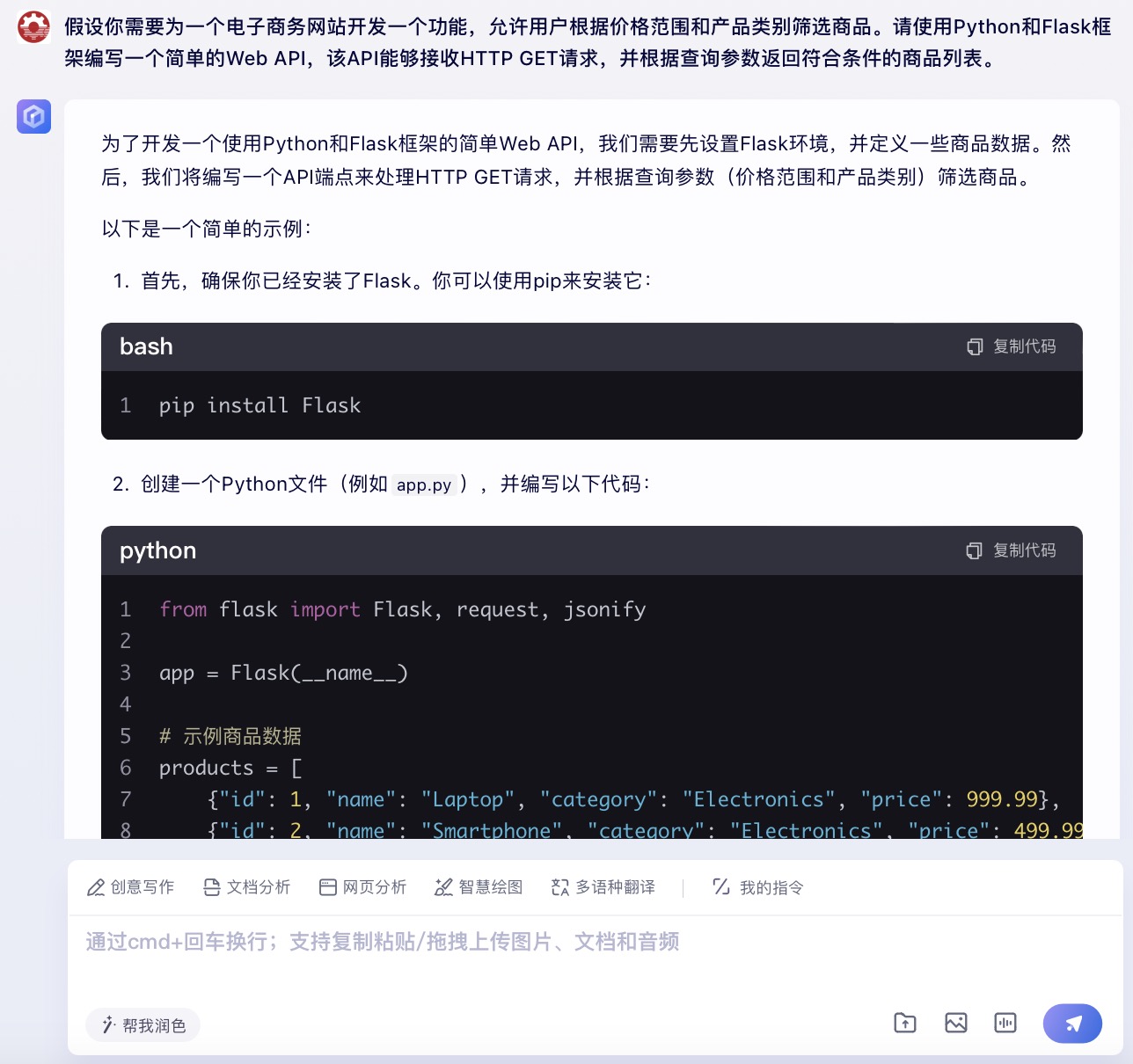
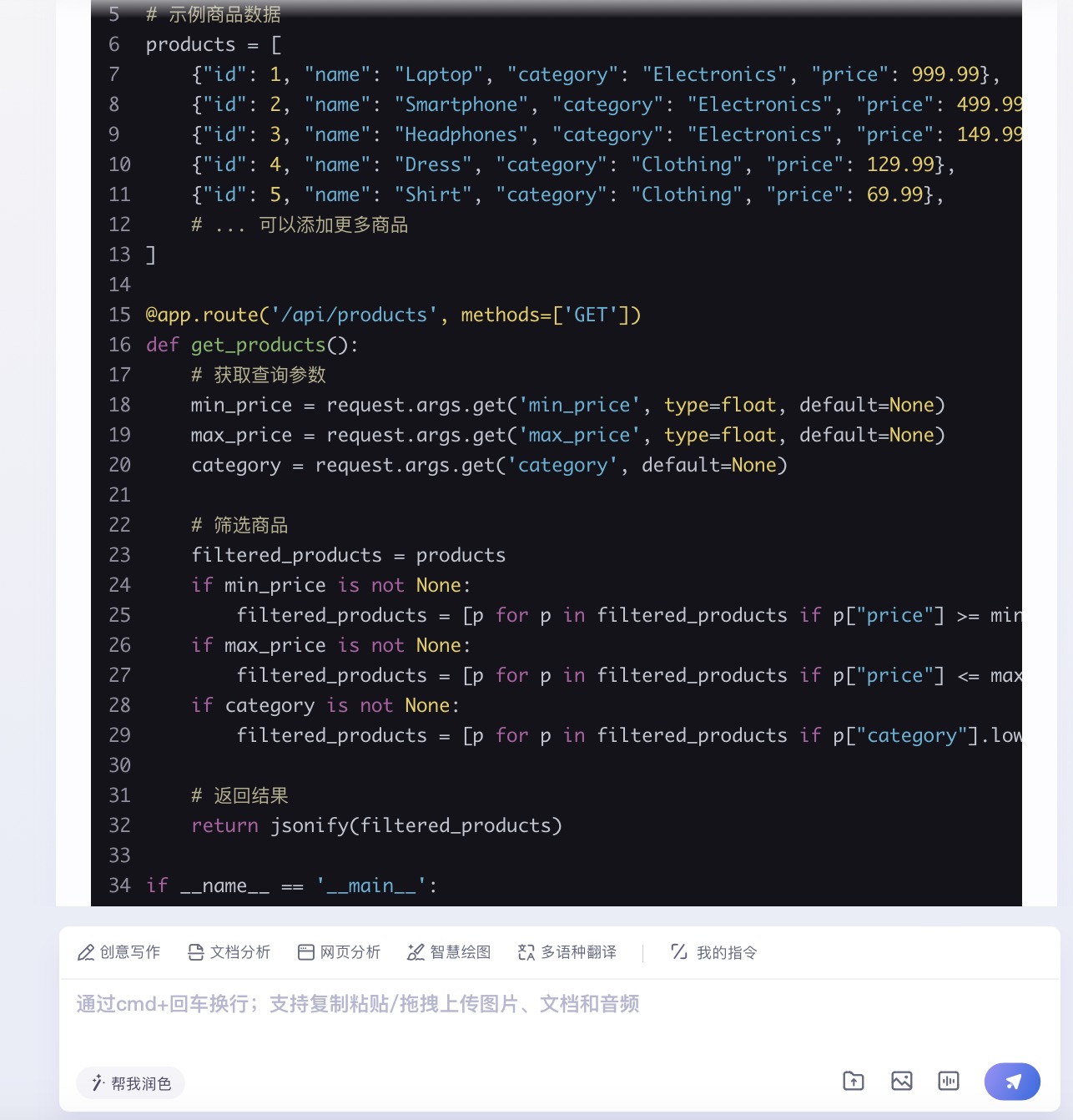
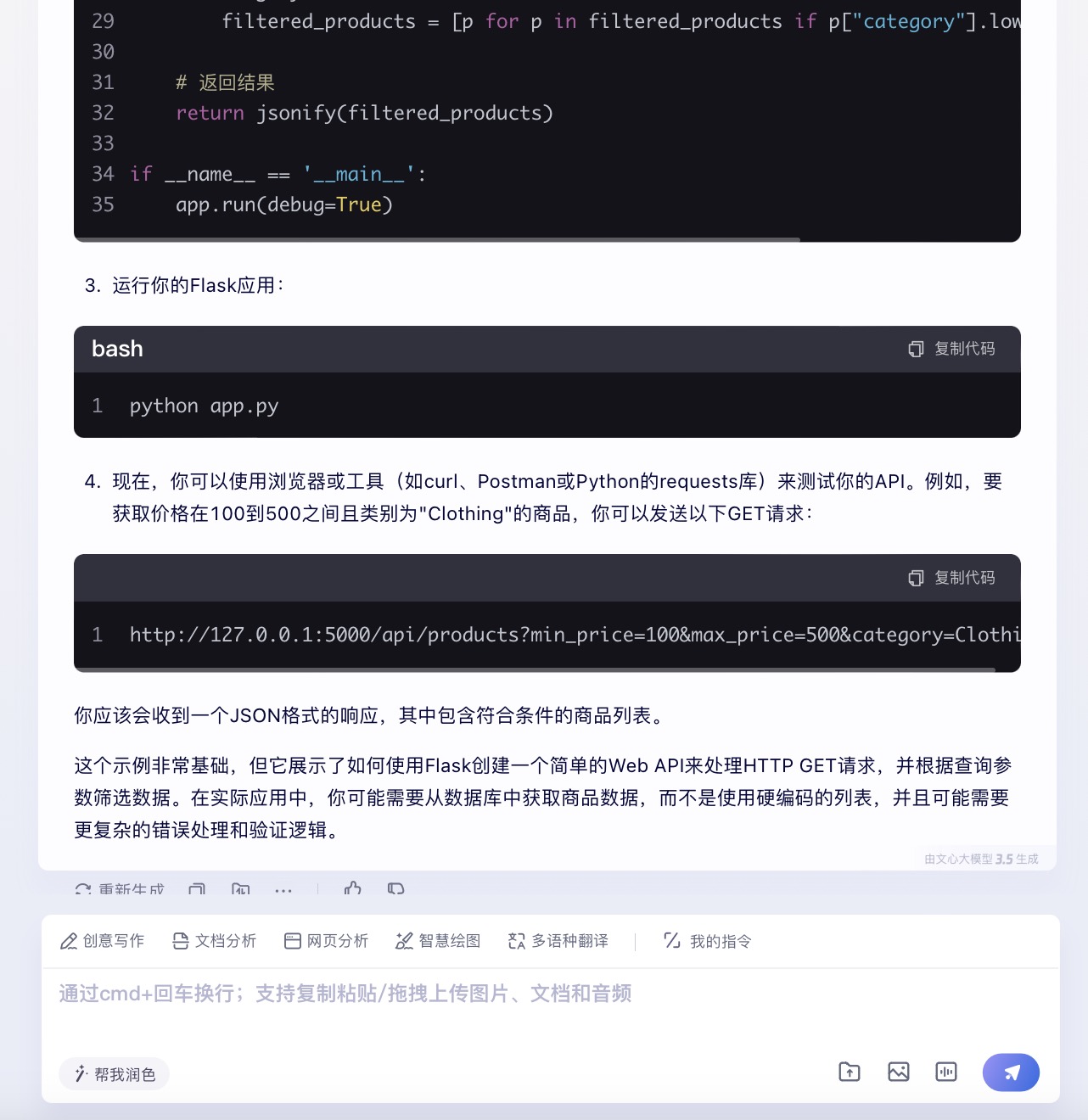
文心一言大模型对问题(6)的回答
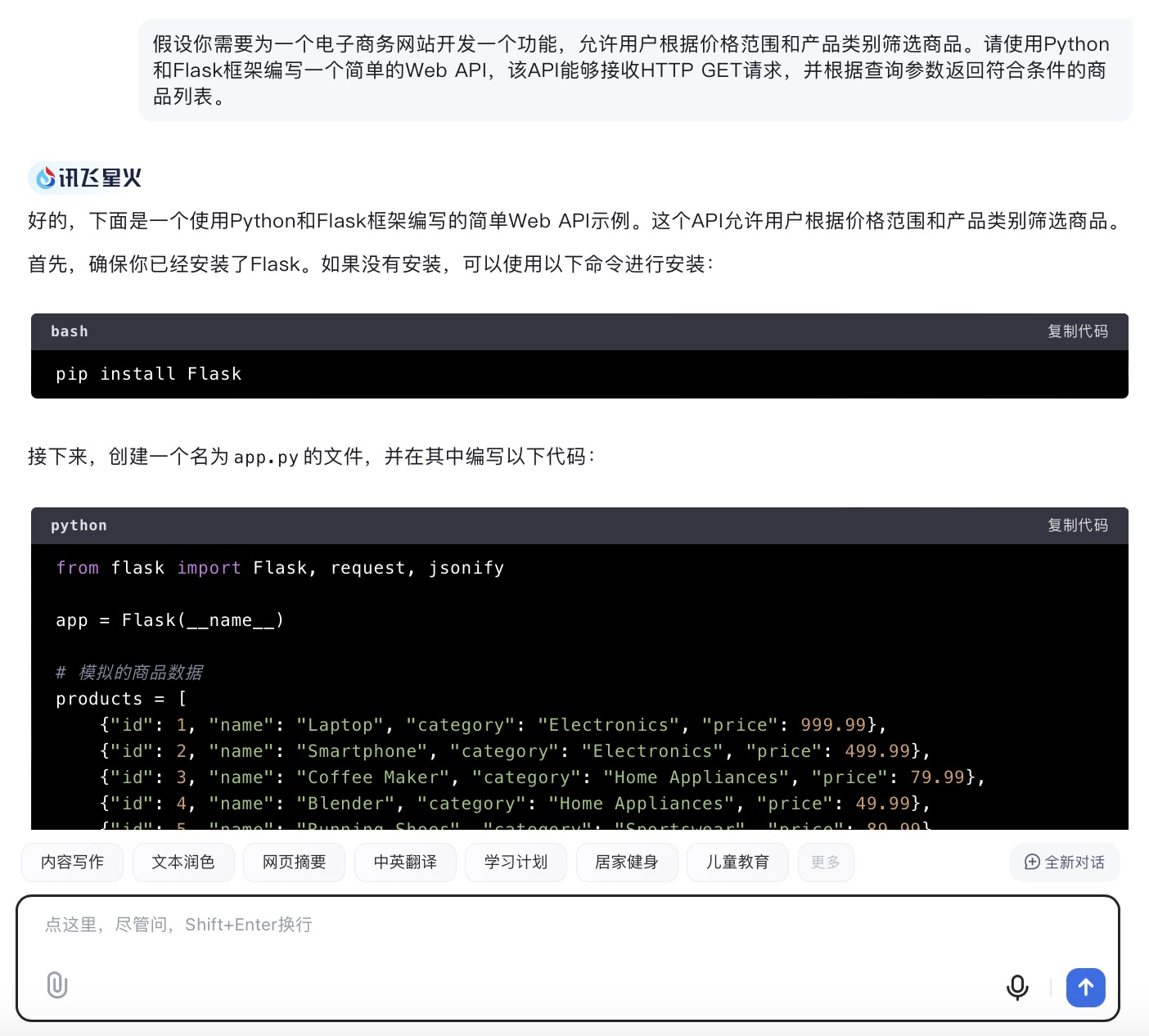
讯飞星火大模型对问题(6)的回答


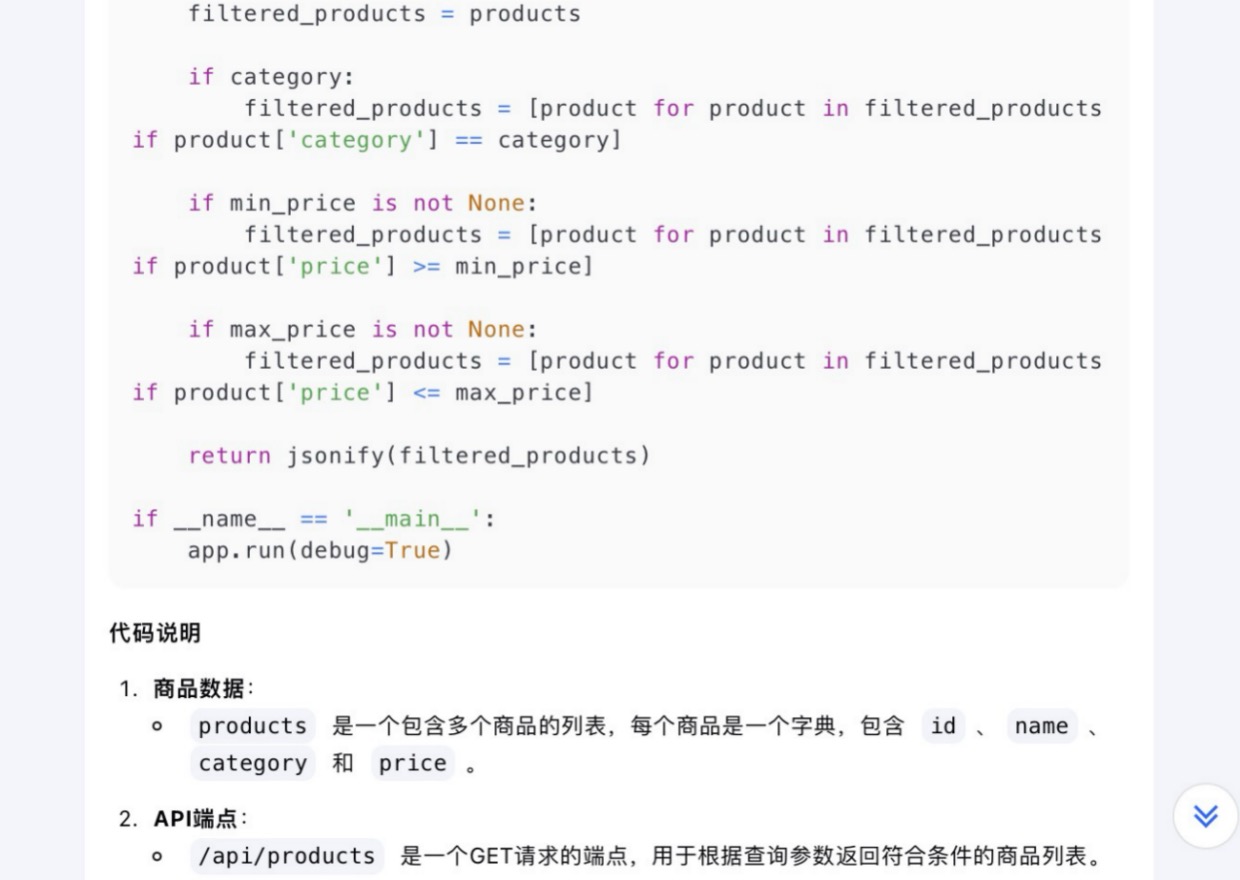

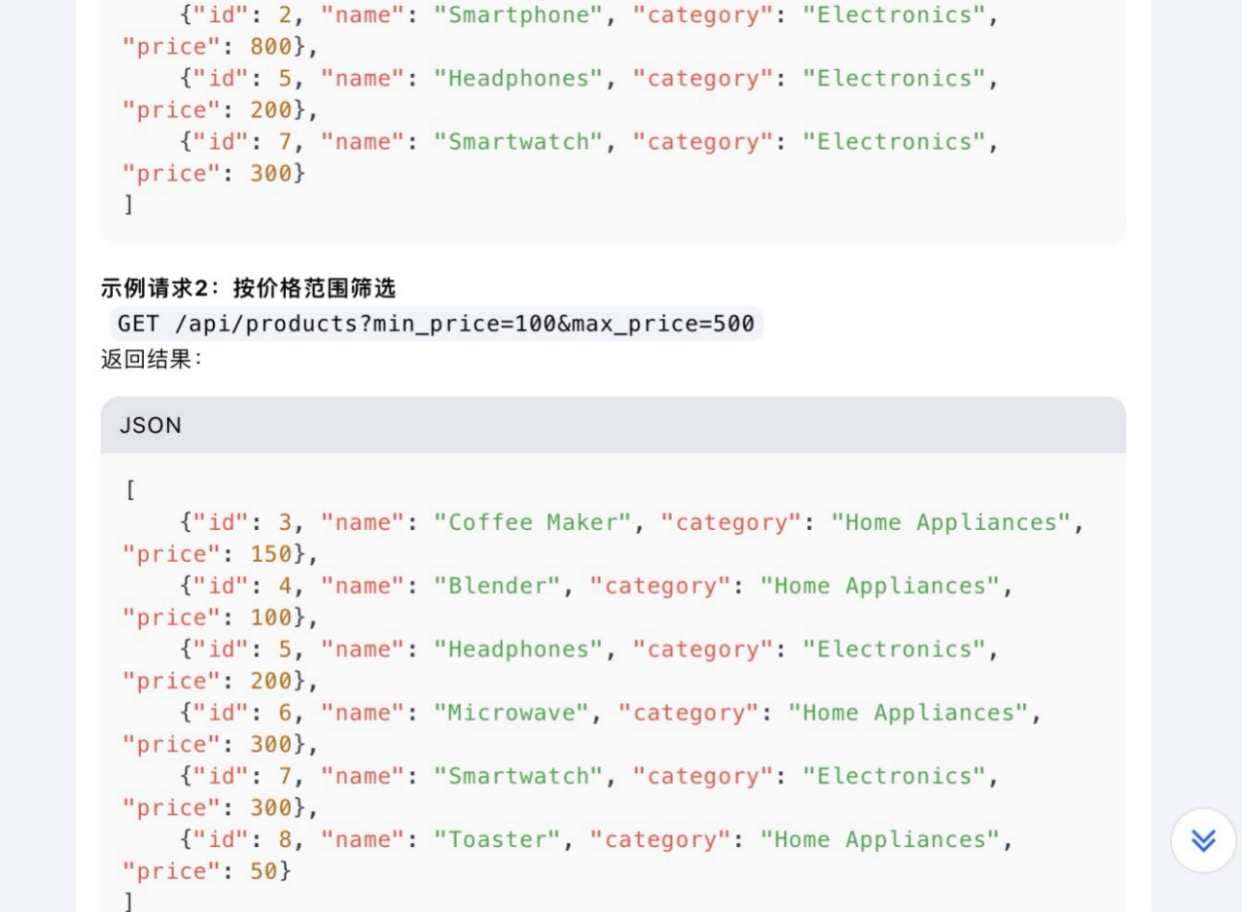
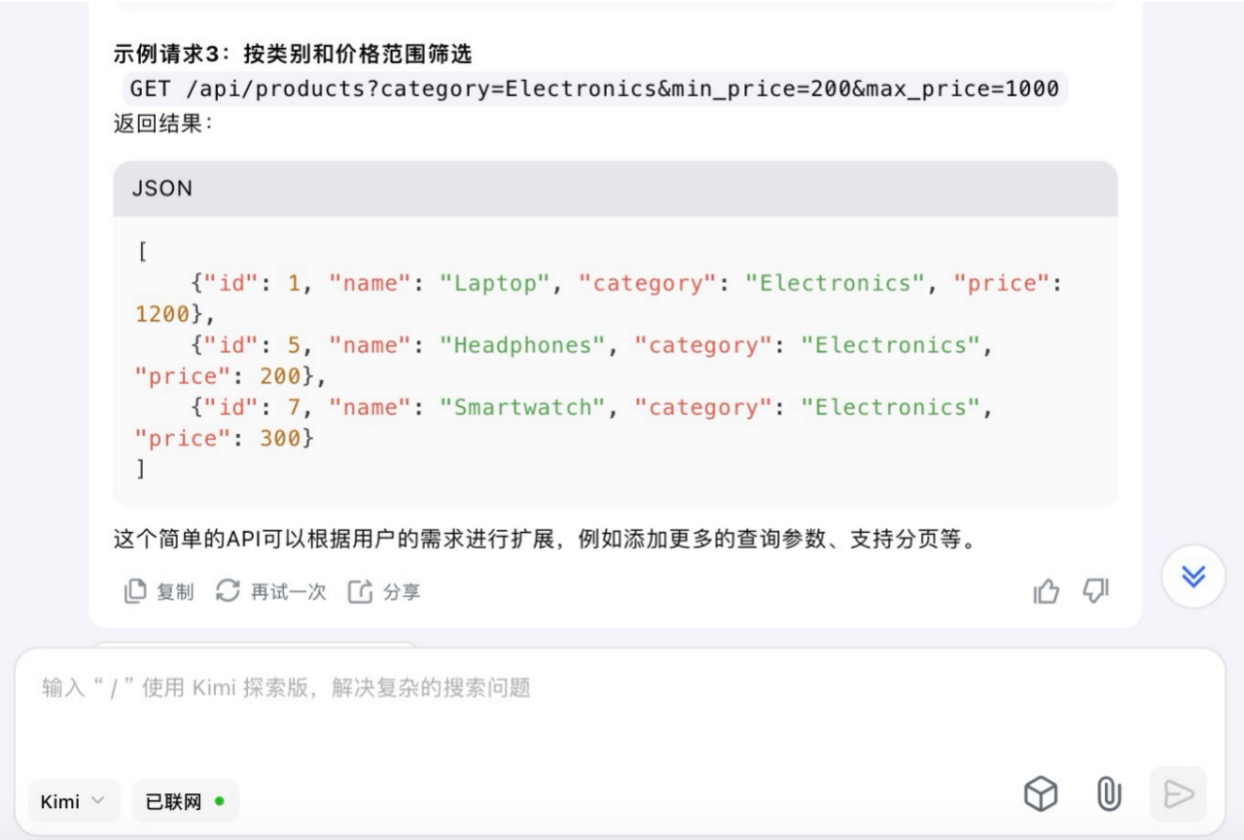
Kimi大模型对问题(6)的回答
问题(6)是考察大模型针对实际业务场景的编程能力。在实现最终功能的过程中,6个大模型均实现对程序开发每一个步骤进行详细的引导和解释,便于用户的理解。足见国内大模型对业务场景编程能力的训练都发展到了一个较高的水平。
(四)文本
(7)请选择一个你最喜欢的季节,详细描述该季节的自然景观、气候特点以及人们的生活状态,字数控制在500字以内。
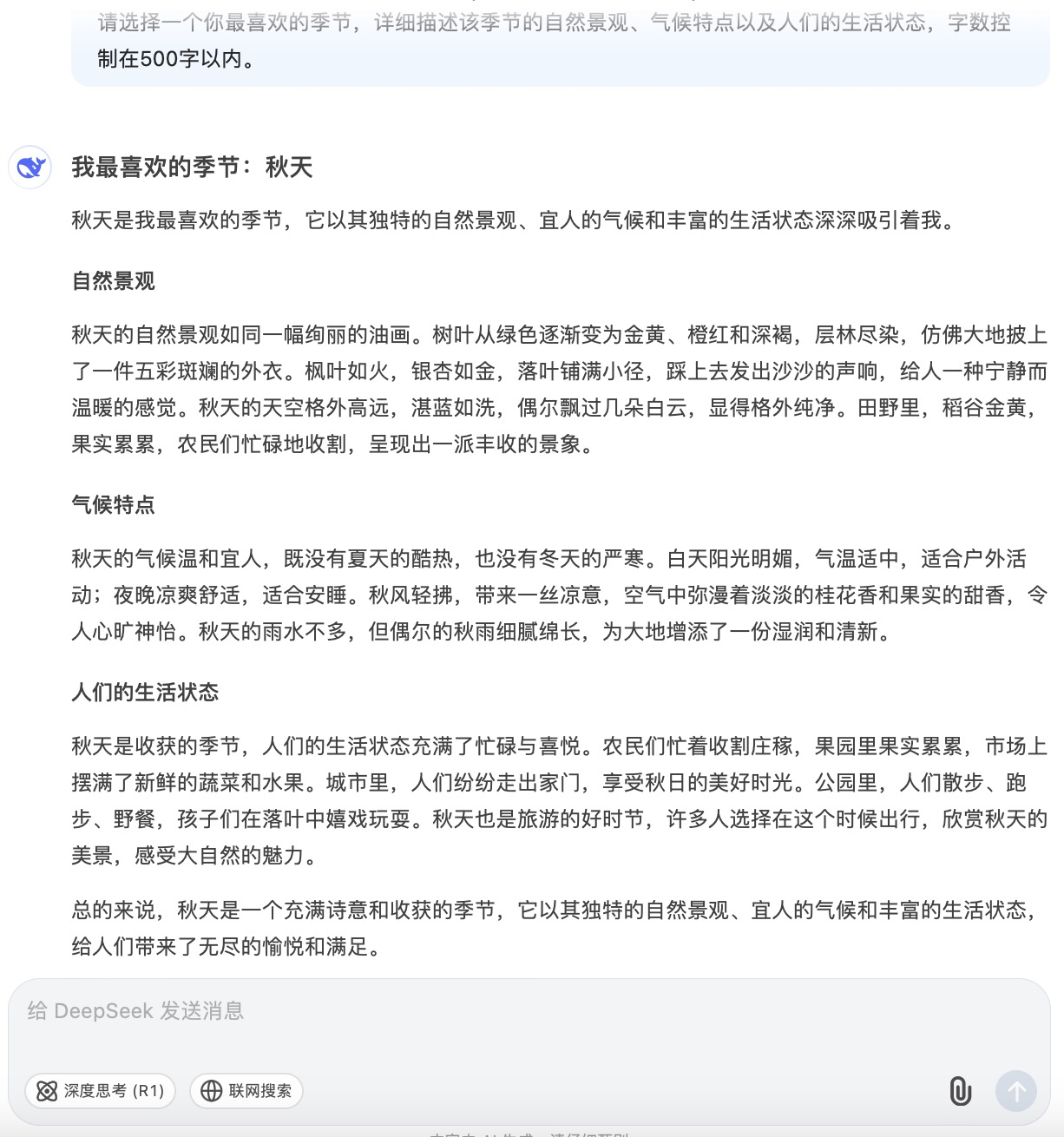
DeepSeek大模型对问题(7)的回答
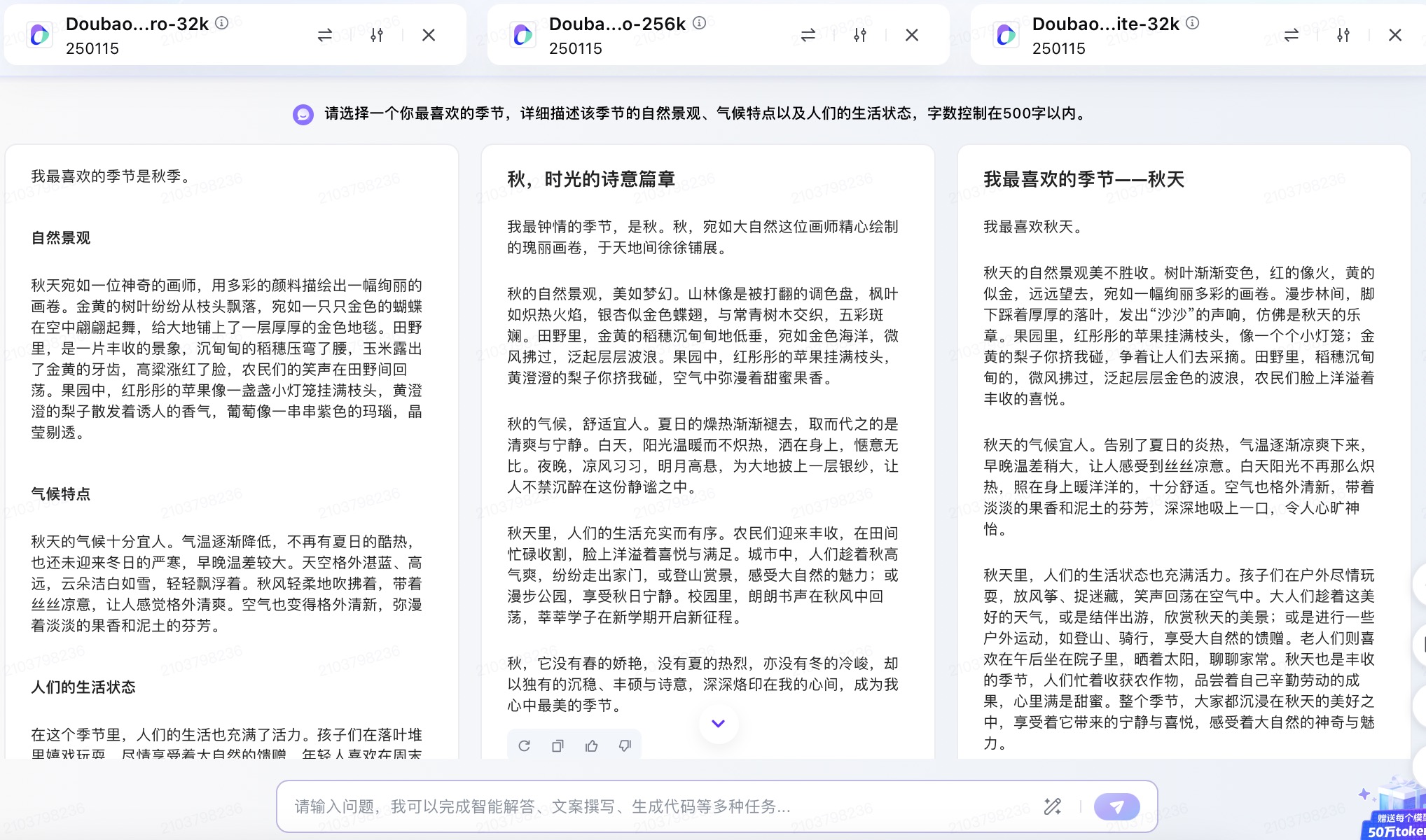
豆包大模型对问题(7)的回答
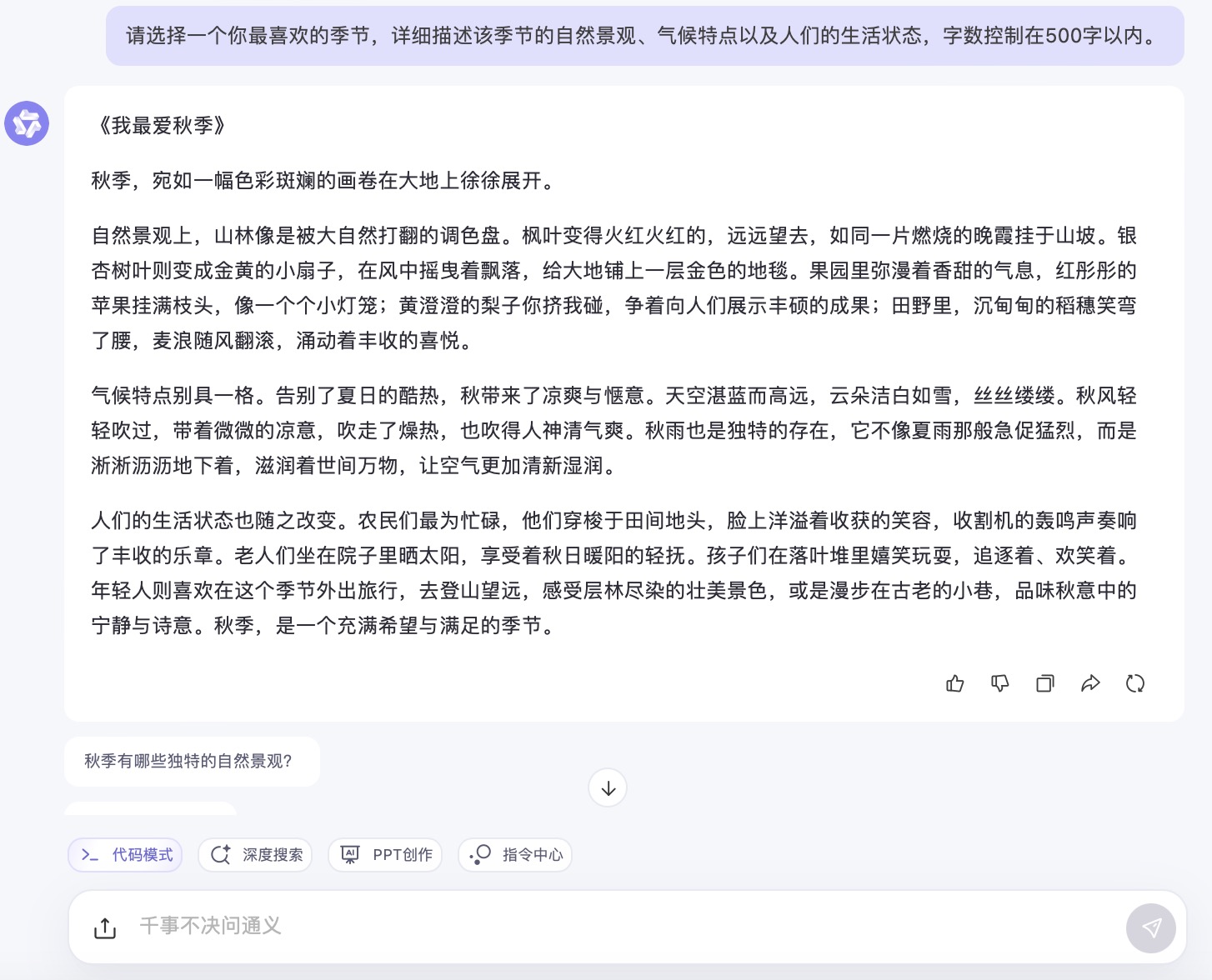
通义千问大模型对问题(7)的回答
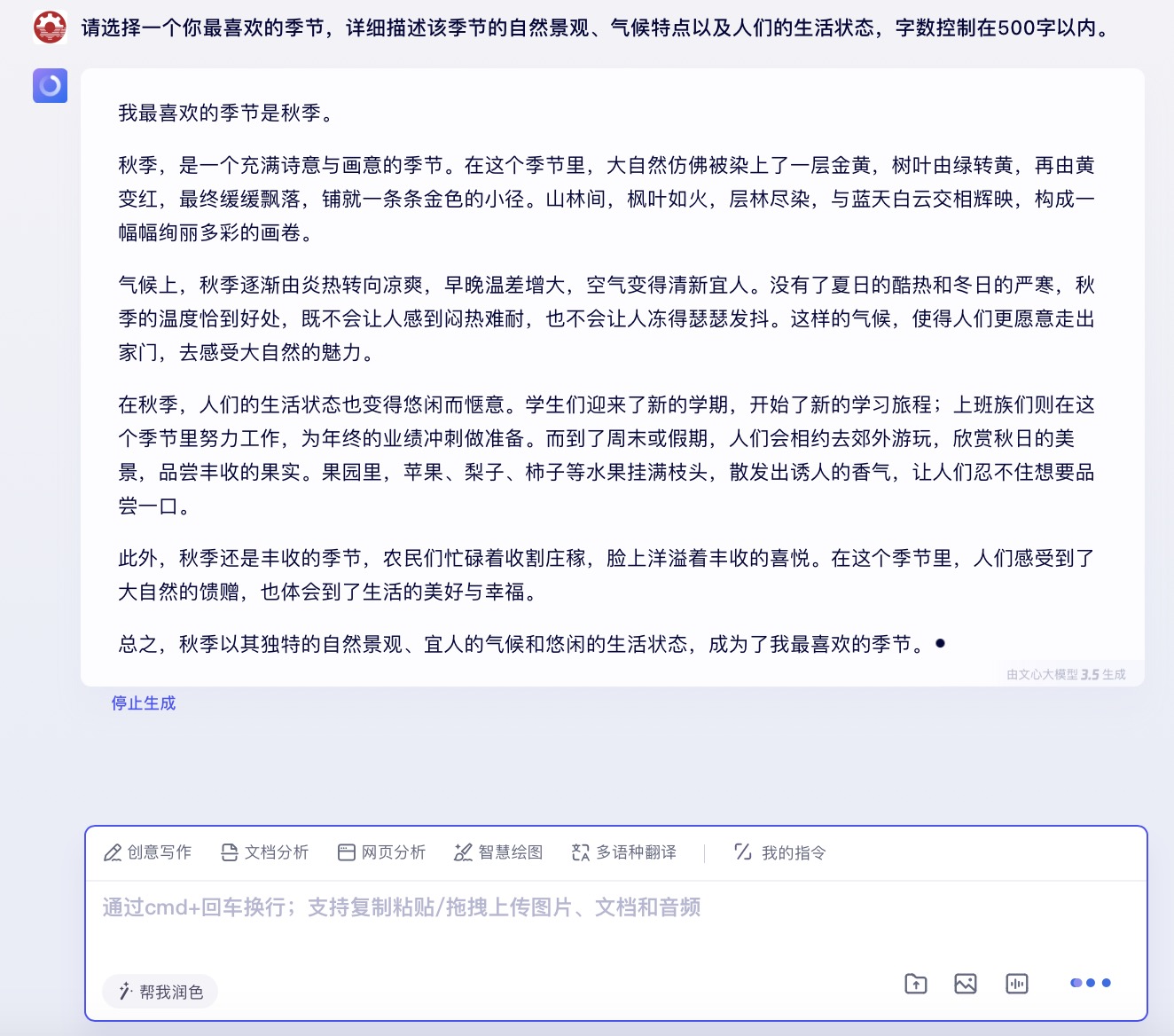
文心一言大模型对问题(7)的回答
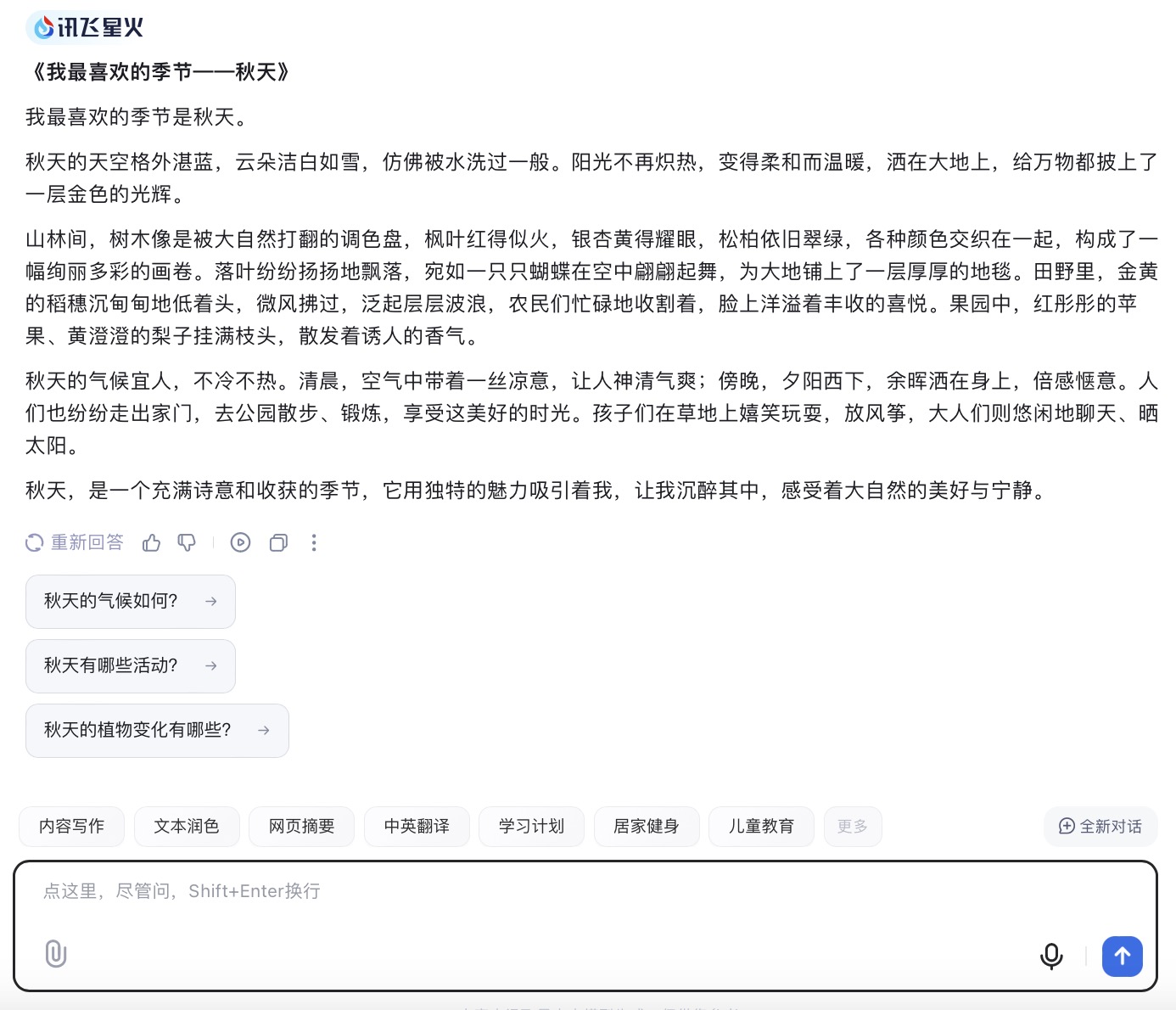
讯飞星火大模型对问题(7)的回答
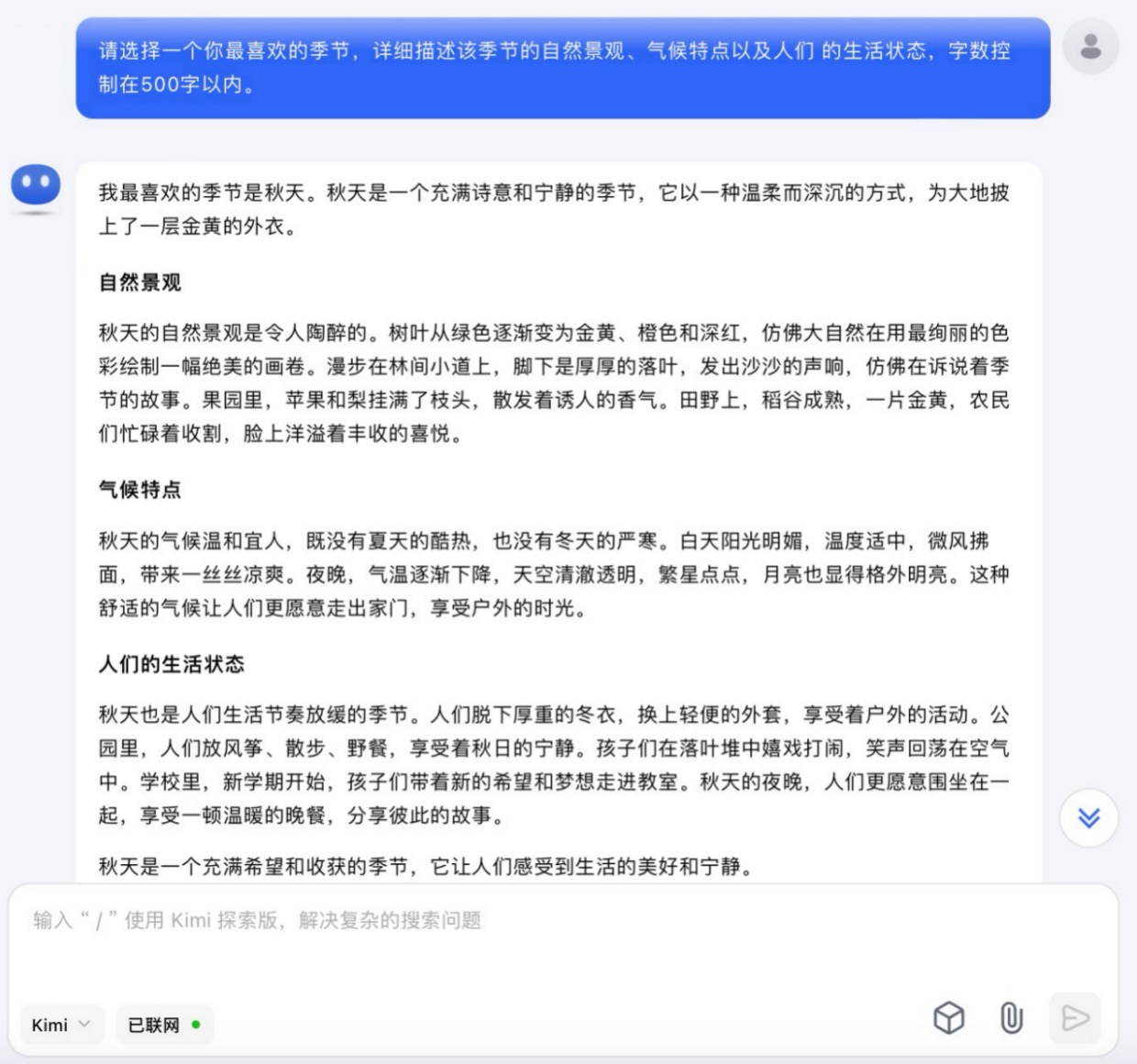
Kimi大模型对问题(7)的回答
问题(7)是考察大模型文字生成和描述能力。针对季节描述的文本内容方面,6个大模型均选择了秋天来叙述,并都能按照要求描述自然景观、气候特点以及人们的生活状态等。在生成文本长度方面,DeepSeek、Kimi略超500字外,其它都严格遵循成文在500字以内。如果要给6篇文章打个分,最高的我给到讯飞星火,行文短小精练,让人看不出模版嵌套的痕迹。
(8)假设你需要向一家公司申请实习机会,请撰写一封正式的求职信。信中需包括 你的教育背景、相关经验和个人优势,并表达你对该公司和实习职位的兴趣。
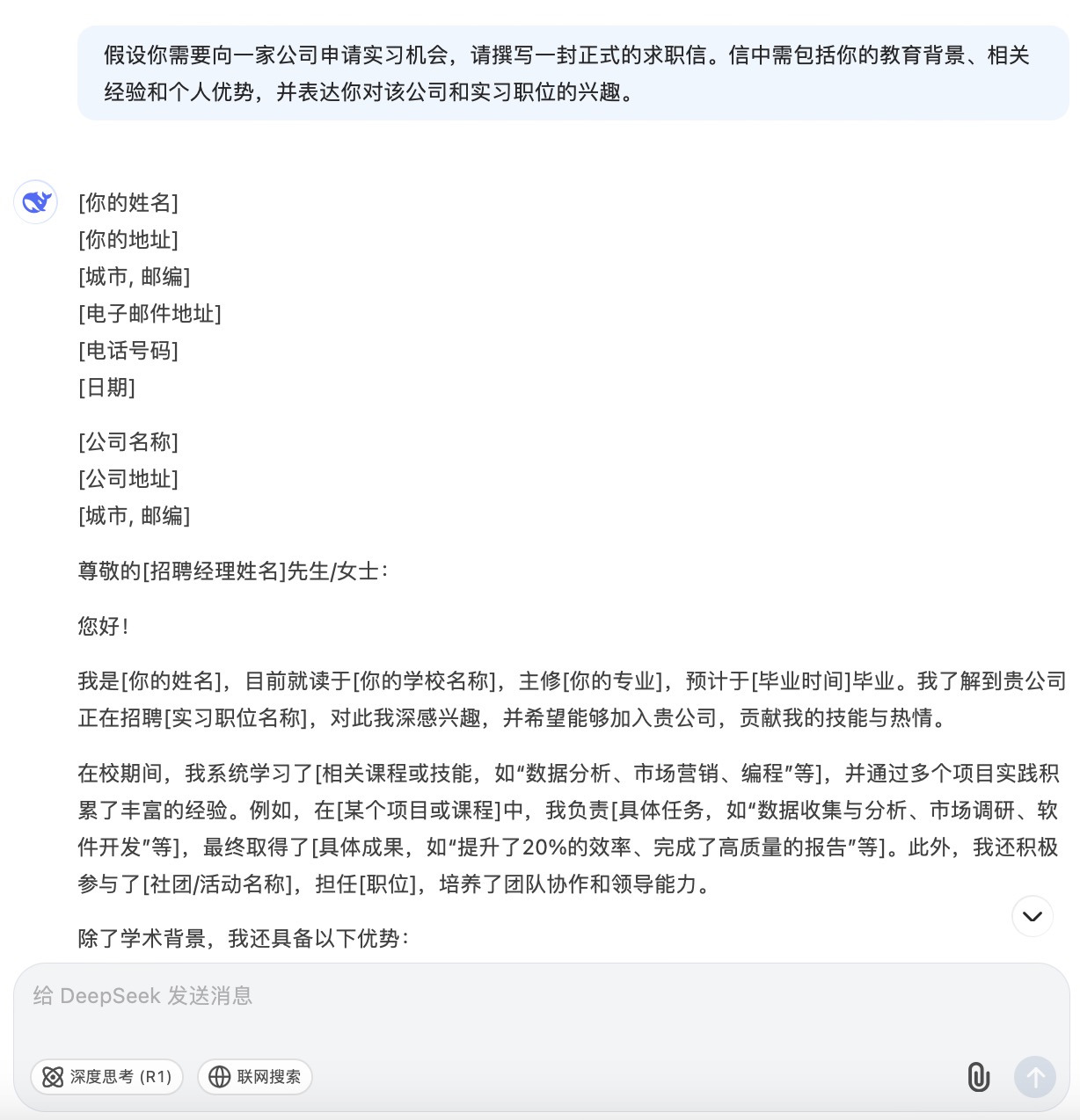
DeepSeek大模型对问题(8)的回答
豆包大模型对问题(8)的回答
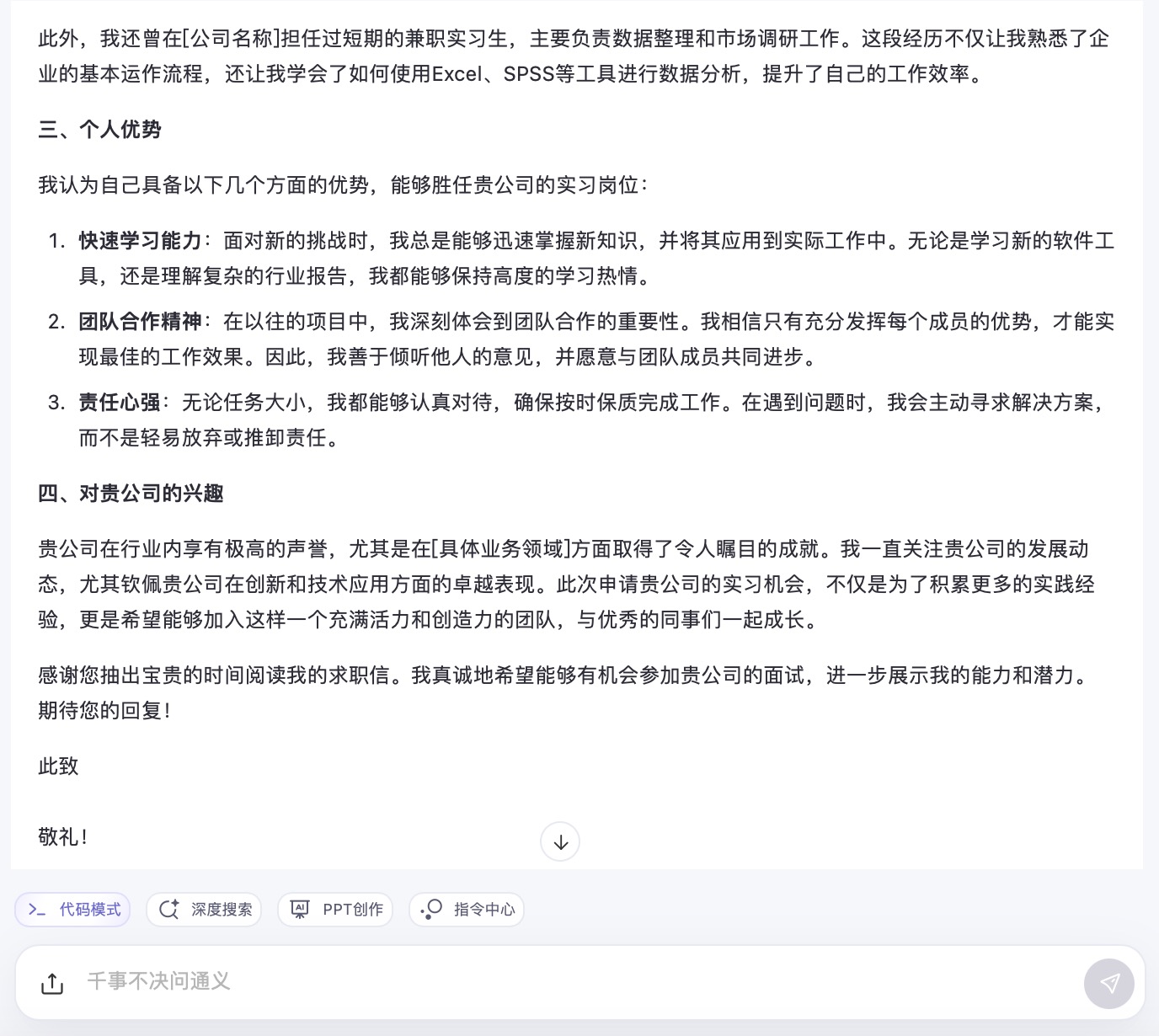
通义千问大模型对问题(8)的回答
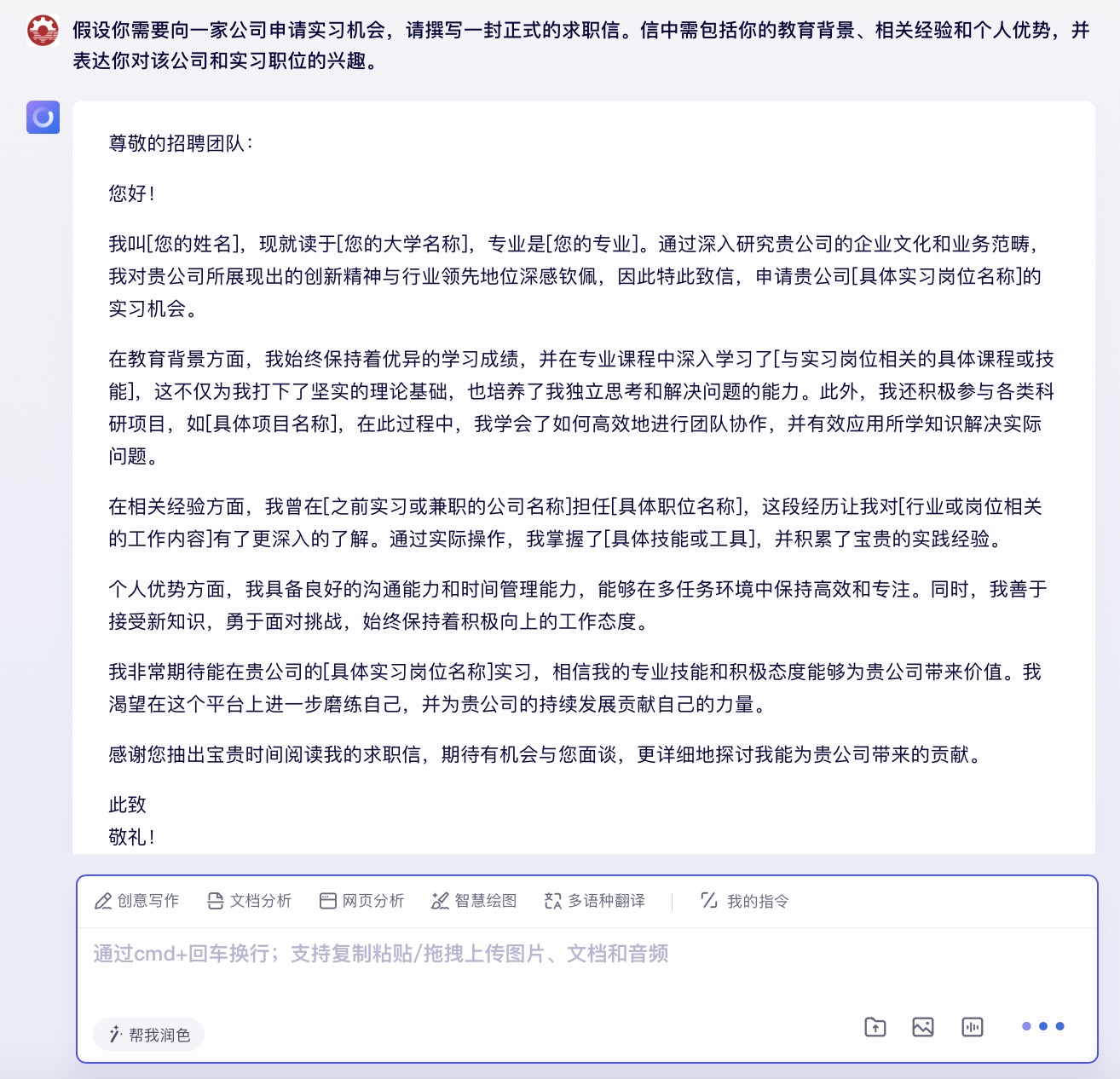
文心一言大模型对问题(8)的回答
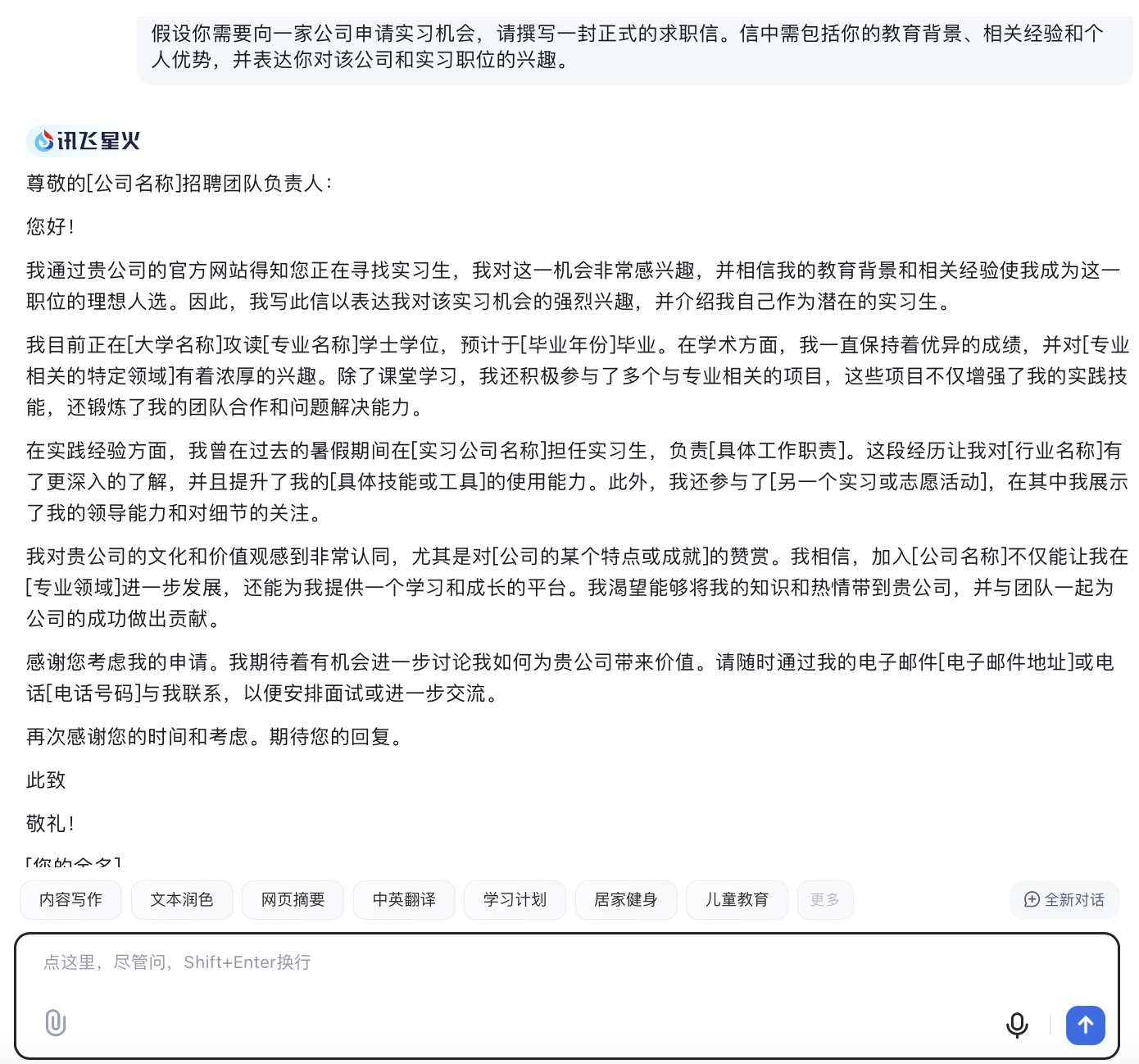
讯飞星火大模型对问题(8)的回答

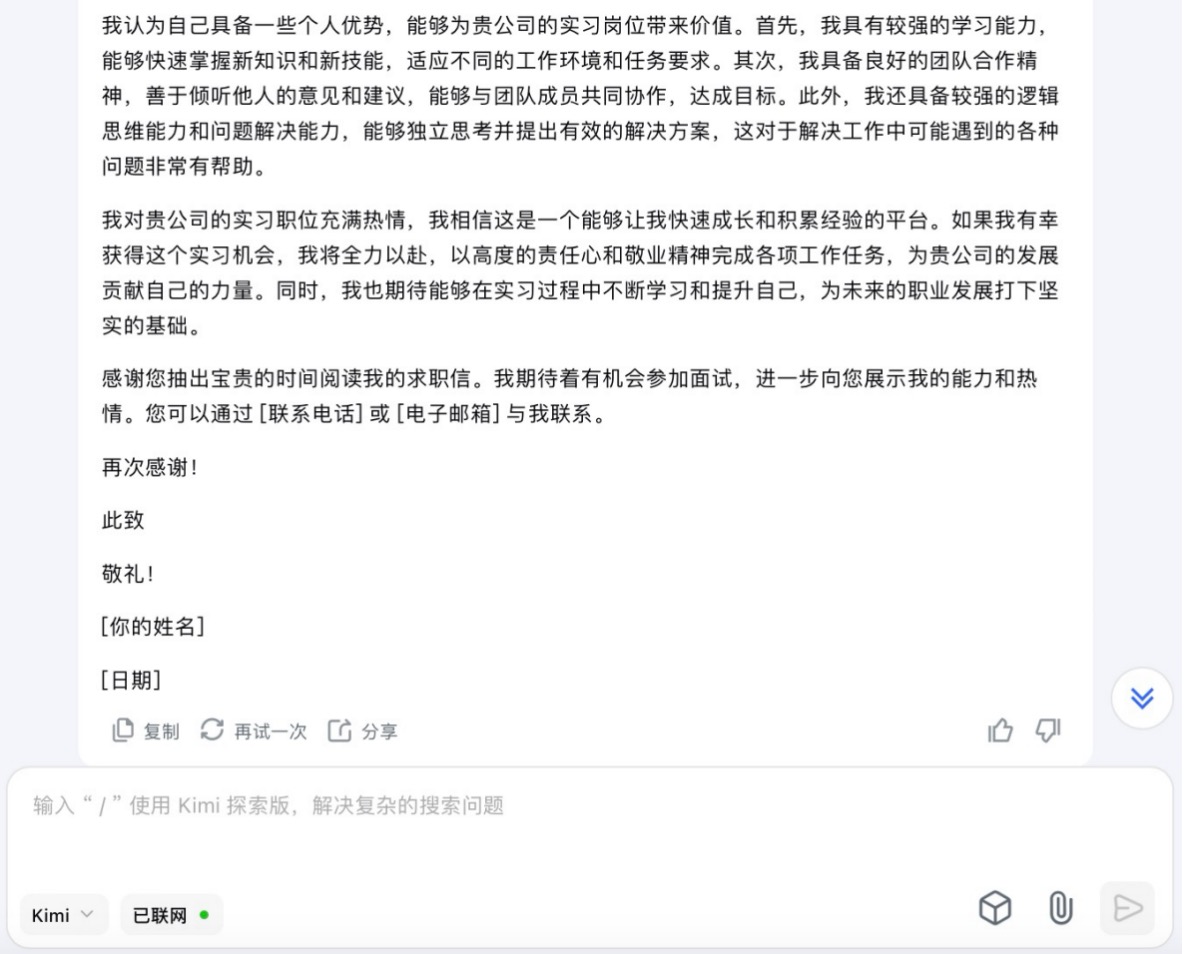
Kimi大模型对问题(8)的回答
问题(8)是考察大模型在具体应用场景中的文字生成能力。针对求职场景的文本内容方面,6个大模型都能按照要求描述教育背景、相关经验和个人优势等,并且针对未提供的信息留有空白给用户自行修改。
通过对比DeepSeek、豆包、文心一言、通义千问、讯飞星火、Kimi这六个大模型回答逻辑、数学、代码和文本等问题的答案。我们发现,DeepSeek总体能力没有短板,与其他大模型相当,DeepSeek在逻辑、数据和代码生成领域具有自身特点和优势。例如,在问题(4)中,仅DeepSeek和豆包两个大模型套用了容斥极值公式,并最终给出了正确答案。在问题(3)中,虽然大多数模型都给出了正确答案,但DeepSeek是唯一给出正确答案且列举例证的模型。在问题(5)中,虽然所有大模型都完成100以内的质数代码编程,但DeepSeek是三个不仅完成代码编写,还输出所有质数结果的大模型之一。在代码生成的任务中,DeepSeek给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。只是在文本生成能力方面,DeepSeek并未展现出明显优于其他大模型之处。
暂无评论,等你抢沙发

对话侯康选: 从“抢修”到“预防”,智能IT运维的正确打开方式

中小企业数字化转型框架与总路线图