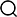导语:本文面向咨询业务领域创造性构建了一套体系完整的AI大模型综合能力评价方法
1 引言
当前,人工智能技术已从“小模型+判别式”转向“大模型+生成式”,国内大模型产品层出不穷,截至 2024 年 8 月,已有190多个能为公众提供服务的生成式AI大模型完成了备案和上线。随着各类 AI 大模型的产品功能不断丰富完善,人们在日常工作与生活中越来越多地使用 AI工具提升工作效率、优化决策过程,对其依赖程度也逐渐增加。然而,大模型行业内看起来火热,实际在咨询行业的用户渗透率极低,其中一个很重要的原因就是 AI大模型种类繁多,导致咨询业务人员即使想用 AI 工具来提升生产力,但不知道该选哪款 AI 大模型。因此,有必要对 AI大模型在咨询业务领域的综合能力进行测评研究,帮助咨询业务人员准确理解各种AI模型的真实性能,选择适合自身需求的AI大模型。
2 大模型能力测评基本思路
本文基于“2W1H”思维模型开展大模型综合能力测评研究与实践,即What(测什么)、Who(给谁测)、How(怎么测)。
2.1 选择测评基准 (明确测什么)
为构建面向咨询业务领域的 AI大模型综合能力评价表,确定评价维度和指标体系成为关键。随着AI大模型的不断推出,对AI大模型能力进行测评已经成为产业界的关注重点,商业公司和研究机构等都纷纷推出了 AI 大模型基准测试(Benchmark)体系,可为 AI 大模型测评指标体系的构建提供参照(表1)。
由表 1 可见,每个 AI 大模型基准测试体系都侧重于不同的评估标准、任务类型和数据集。虽说测评体系是衡量通用人工智能能力水平的基准,但当前还没有固定统一的绝对标准,因为AI大模型的发展速度非常快且种类繁多,不同领域所关注的评估方法和评价指标也不尽相同。尽管如此,大模型测评的意义在于在目标领域对不同AI大模型的综合能力进行评价和比较。
表1 典型的AI大模型基准测试 (Benchmark) 体系

与其他 AI 大模型基准测试体系相比,SuperCLUE测评体系更加丰富和多元化,其生成与创作、长文本、智能体、多模态、智能座舱、行业等测评场景与咨询业务人员的日常使用需求更为吻合。因此,从咨询业务领域的适用性角度考虑,本次测评选择了SuperCLUE作为参照基准。此外,考虑到咨询业务人员在文本类方面的应用需求更为迫切,因此在制定AI大模型能力评估体系时会有所倾斜,着重评估AI大模型在文科方面的能力。
2.2 选择测评对象 (明确给谁测)
当前,国内各大科技公司纷纷推出自家AI大模型,这些产品在技术上各具特色。本文结合咨询业务对AI大模型的需求特点,将文本生成、智能问答、多模态理解等核心能力突出的生成式AI大模型初步定为测评对象;与此同时,考虑到咨询业务人员在Web端使用AI大模型更加便捷,又根据Web端用户活跃度情况对测评对象进行进一步筛选,最终选取通义千问、Kimi、文心一言、豆包、讯飞星火、天工等6款AI大模型作为重点测评对象。
2.3 选择测评方法 (明确怎么测)
鉴于AI大模型对于开放式主观题问答所生成的内容没有统一标准答案,故本文通过人工评判的方式考察 AI大模型的综合能力,对于提问任务的设定成为关键。因为虽说 AI大模型对于文本类工作的处理效率惊人,但 AI大模型的表现更多依赖于使用者所提问题的质量,只有清晰、结构化的提问才能大大提高 AI 大模型回答的准确性和质量。尽管 AI 大模型一直处于升级之中,会带来理解能力的提升,但如果问题描述不清晰,就远远不足以激发出 AI大模型的溢出能力。
可以说目前阶段使用 AI大模型最核心的门槛就是如何更科学地提问,让 AI 大模型充分理解使用者的真实意图并提供高质量的回答。在本次测评中,为了避免提问任务设定本身影响测评结果,本文参考了 OpenAI官方教程中给出的撰写提示词 Prompt建议以及主要框架:①R-T-F(Role角色,Task任务,Format格式);②T-A-G(Task 任务,Action 行动,Goal 目标);③I-S-E(Input 输入,Output 输出,Expectations 期望);④B-A-B(Before之前,After之后,Feedback反馈);⑤C-A-R-E(Content内容,Action 行动,Result结果,Example 示例)。同时在正式测评之前,采取了切换提问方式、模型之间对比检查等措施确保所设定的提问任务质量。
3 测评指标体系与任务设定
在大模型能力测评研究方面,周立炜等采用人工评估和指标评估相结合的方式,从语体分类、语体生成和语体转换三个方面评测了 ChatGPT、文心一言、讯飞星火等大模型的中文语体能力。郭亚军等从需求锁定、信息扩展、偏好响应、检索改进四个方面设定了准确性、契合性、满意度、创新性、逻辑性五个评分指标,每个指标的满分值设定为10分,采用专家打分法对 ChatGPT 进行测评。赵浜等将 ChatGPT 类大模型的基本能力划分为对比、计算、转换、拓展、推理、总结、分类、检索、编程九个方面,设定了准确性、逻辑性、完整性、易读性四个评分指标,每个指标的满分值也都设定为10分。可见,已有研究大多面向人文社科领域,缺乏面向咨询业务领域的大模型能力评价方案;且在构建评分体系时相对单一,没有赋予各测评指标相应的权重,未进行加权分析,可能会造成测评结果的片面性。
本文在参考相关研究文献评分指标体系的基础上,以满足咨询业务人员的日常使用需求为出发点,对照 Super⁃CLUE 测评基准的测评维度,从成本与易用性、文本生成与创作能力、多模态能力、长文本理解分析能力、数据分析决策能力、音视频听悟能力、智能体能力、行业相关性等 8个方面,自主构建了一套咨询业务领域的AI大模型综合能力测评指标体系(表 2)。值得注意的是,与其他研究中大多采取的简单赋予各评价指标相同满分值的评价方法所不同,本文在对各能力测评维度设定满分值时,创新性地考虑到了权重的分配并进行加权分析,因为加权分析数据能够更为准确真实地反映出各大模型的综合能力。众所周知,测评体系中的各能力维度优先级并不相同,比如对于咨询业务人员的日常使用而言,生成与创作、多模态等能力维度在咨询业务领域的使用更为重要。在具体权重分配时,本文主要从以下几个维度进行综合考量:日常使用的贴合程度、工作任务的优先顺序、对工作成果的影响程度、对日常使用影响的责任高低等,满分值越大,代表该评分指标的权重越高。
表2 咨询业务领域AI大模型能力测评指标体系
根据基本思路处提及的测评方法,本文针对上述8项能力测评维度,参照日常咨询业务开展过程中的真实工作任务内容,分别设定了共计 10个提问任务(表 3),用于与各 AI大模型的测评互动。
表3 各能力测评维度的提问任务Prompt示例

4 大模型能力测评结果分析
如前文所述,本文主要以统一的主观题问答互动形式对AI大模型生成内容进行人工评判。为了保证测评过程的严谨性和测评结果的公平公正,在测评时邀请了由公司咨询专家和一线咨询从业人员组成的测评小组参与评分,并确保相关测评人员均能够熟练使用 AI大模型、能够准确理解此次测评流程和评分标准,进而给出客观合理的评分。最终,测评小组针对通义千问、Kimi、文心一言、豆包、讯飞星火、天工等 6 款AI大模型的测评结果如图1所示。
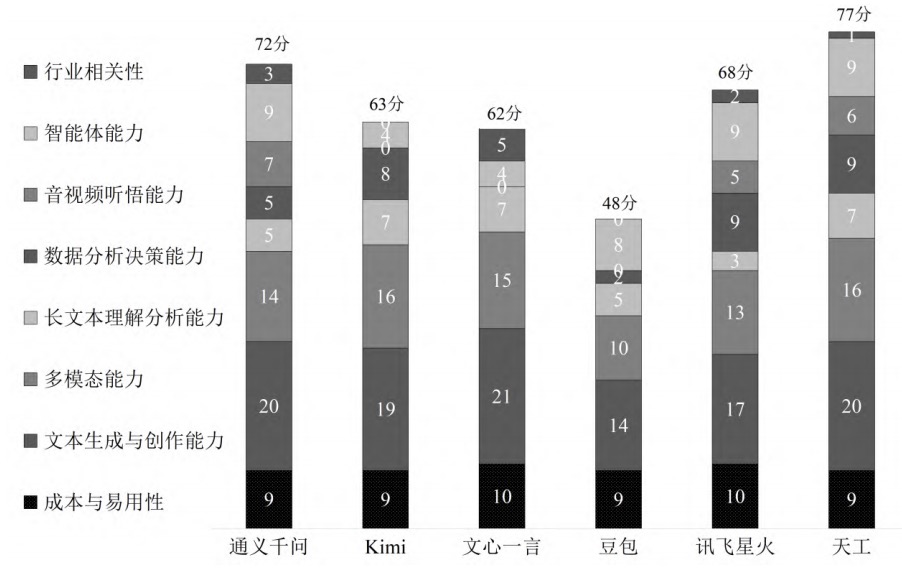
图1 各AI大模型测评得分对比图
此外,本文还对AI大模型的各维度得分进行归一处理,使分值不同的各指标之间具备可比性,得到的归一化分值对比情况如图2所示。
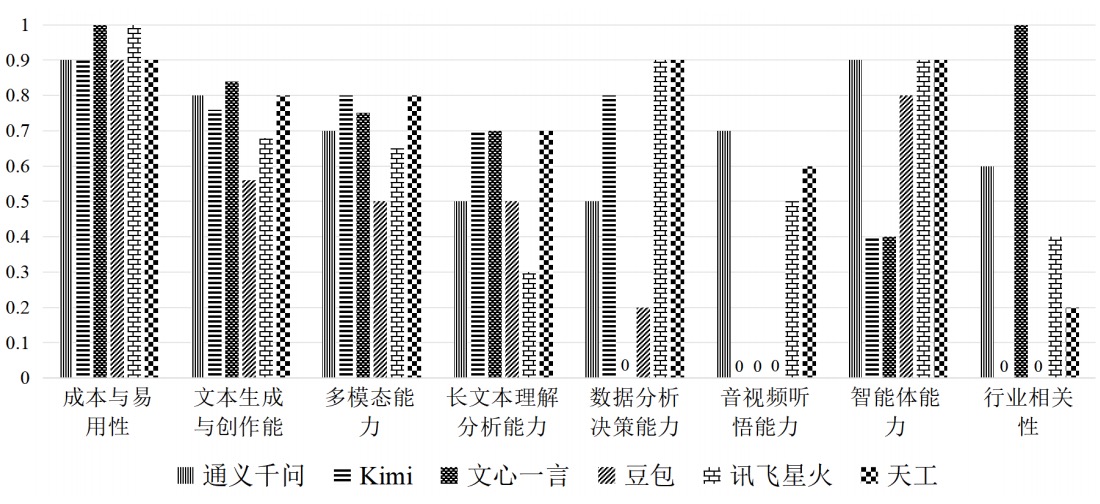
图2 各AI大模型的能力测评归一化分值对比图
经测评,本文认为,在咨询业务领域,通义千问、Kimi、文心一言、豆包、讯飞星火、天工6款AI大模型的表现如下:
(1)从总分来看,天工的测评得分最高,在咨询业务领域的综合能力最出色;通义千问与讯飞星火紧随其后,Kimi与文心一言稍逊之;豆包的测评得分最低,表明其在咨询业务领域的综合能力存在明显不足。
(2)各 AI大模型在成本与易用性、文本生成与创作能力、多模态能力、智能体能力等方面的得分普遍较高,这表明国产AI大模型的核心功能基本免费供大众使用,且大多展现了出色的文本生成创作、文生 PPT、文生表格、文生图、文生大纲等能力,适合在开展日常咨询工作时上手使用。
(3)在成本与易用性方面,文心一言与讯飞星火的得分最高;在文本生成与创作能力方面,文心一言的得分最高;在多模态方面,Kimi与天工的得分最高;在长文本理解分析能力方面,Kimi、文心一言与天工的得分最高;在数据分析决策能力方面,讯飞星火与天工的得分最高;在音视频听悟能力方面,通义千问的得分最高;在智能体能力方面,通义千问、讯飞星火与天工的得分最高;在行业相关性方面,文心一言的得分最高。
5 结语
AI技术通过全面作用于劳动力、劳动资料和劳动对象,将对经济运行和社会发展产生重大影响,并为新质生产力提供不竭动力。本文研究探索了如何将AI大模型引入咨询业务的生产运营中,从咨询业务人员使用的角度对当前市场上表现较为突出的 AI大模型进行了客观全面的测评,对咨询业务人员而言具有一定的普适性及指导意义。咨询业务人员应积极拥抱 AI 大模型时代,学会充分利用 AI 大模型的“机器人”和“图书馆”属性,优化一些耗时且劳力密集的基础工作流程,使咨询业务工作效率和咨询方案质量得到显著提升,以此激发咨询业务人员的创新活力,进一步探索 AI大模型在企业咨询业务链价值链的覆盖应用,为企业咨询业务的发展构筑新的核心竞争力。
原文刊载于《通信与信息技术》2025年第1期 作者:中通服咨询设计研究院有限公司 唐亚平 王莹
暂无评论,等你抢沙发

对话侯康选: 从“抢修”到“预防”,智能IT运维的正确打开方式

中小企业数字化转型框架与总路线图